

こんにちは!機械学習講師の船蔵颯です。この記事は Word2Vec という技術について、下記のような方を対象に解説します。
- 機械学習・深層学習の初学者で、特に自然言語処理に関心がある
- 自然言語処理で頻出する「Word2Vec」が何か知りたい
この記事では、Word2Vec に親しむことを目標にしています。
まずは概要を掴み、その後に Python 上で動かしてみましょう。この記事はあくまで入門を目指しているので、具体的なモデリング手法の解説は省略しています。より詳しい内容については別の機会に譲ることにします。

DX を推進する AI ・データサイエンス人材育成コース
プログラミング未経験から、AI やデータサイエンスを学ぶことのできる 6 ヶ月間のコースです。転職実績も豊富で、自走できる AI人材を多く輩出しています。
Word2Vec とは
Word2Vec は自然言語を数ベクトルで表現する手法の一つです。中でも、Word2Vec は単語をベクトルで表現する手法です。下図はそのイメージです。

より正確には、Word2Vec は Mikolov らが 2013 年の論文 (Efficient Estimation of Word Representations in Vector Space, ベクトル空間における単語の表現の効率的推定, https://arxiv.org/abs/1301.3781) で発表した一連の手法です。
モデルとして CBoW 、Skip-Gram の二種類、最適化戦略として階層的ソフトマックス、負例サンプリングの二種類を含みます(この記事では詳しい説明を省略します)。
「単語がベクトル空間で表現される」というのはイメージが湧きにくいかもしれません。要するに、これは単語を空間内の点で表現するということです。
下図の Embedding Projector (https://projector.tensorflow.org/) では、単語が点で表現される様子を幾何的に見ることができます。
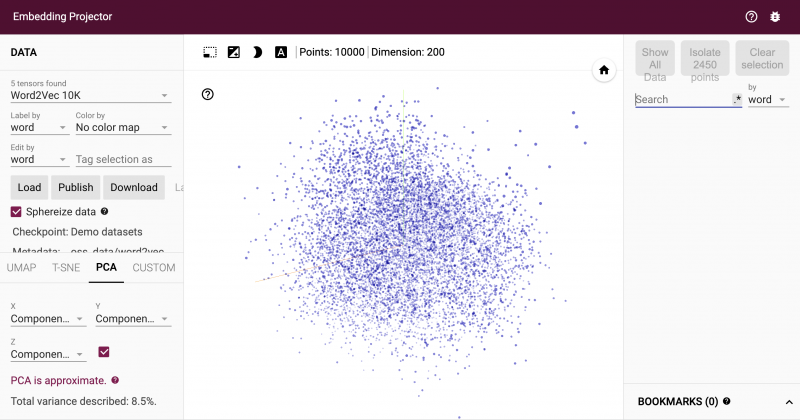
この記事ではモデルや最適化の詳細には踏み込まず、単語のベクトル表現というアイデアに親しむことを目指します。
Word2Vec は単語の「ベクトル表現」
単語をベクトルで表現するというアイデア自体は Word2Vec 以前から広く受け入れられていました。単語のベクトル表現には次のような利点があります。
- ベクトルで表現することにより、単語間の距離や内積が定義され、単語間の「近さ」を定量化できる
- 数値によって表現されていることから、機械学習モデルへの入力として用いることができる
Word2Vec と従来法との違いは、単語のベクトル表現をニューラルネットワークの学習を通じて獲得する点です。この方法により、従来法の抱えていた諸問題(例:次元過大の問題、データスパースネス問題)を回避することができます。
Word2Vec にはじまるこのアイデアはその後も受け継がれ、最近の自然言語処理モデルでは必ずといってよいほど活用されています。ちなみに、ニューラルネットワークの表現学習によって単語ベクトルを獲得する手法は単語埋め込み (word embedding) と呼ばれています。
次節では、上記の二つの利点のうち単語間の「近さ」を定量化できるという点に注目して、簡単に解説します。
類似度:ベクトルであることの恩恵
ベクトル空間には距離や内積が定義されているため、単語のベクトル表現によって単語間の「近さ」を定量化することができます。この近さにはさまざまな計算方法がありますが、総じて類似度と呼ばれています。
単語間の類似度には、次のような使い道があります。
- 獲得したベクトル表現の評価
各単語のベクトル表現たちが、人間の言語直感に沿うものになっているかを評価する際に利用することがあります。 - 自然言語処理タスクへの応用
自然言語推論や機械翻訳などのタスクに活用することがあります。
この節では、単語ベクトルが「近い」ということのイメージを掴むことを目指します。先ほどご紹介した Embedding Projector を用いて、近くにある単語をリストアップすることができます。ここでは試しに “computer” という単語について調べてみましょう。
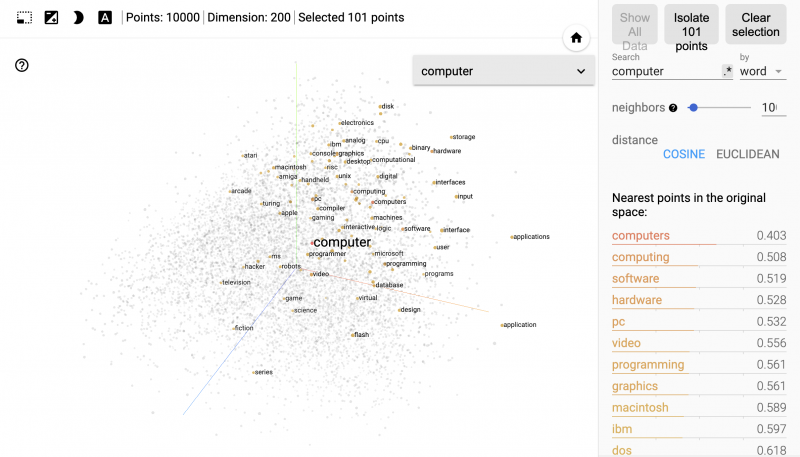
画面中央には、 “computer” との類似度が高い単語たちが強調されています。また画面右側で類似度の具体的な値を見ることができます(nearest points は「最も近い点」くらいの意味です)。
ここで使っている類似度の指標はコサイン距離と呼ばれるもので、0 に近い値であるほど類似していると解釈できます。
近くにある単語としては “computing” 、“programming” 、“software” などが挙がっており、直感的に “computer” と近い単語が、空間内で近くに写像されていることがわかります。
Word2Vec に触れてみましょう!
さて、ここまでは Word2Vec の大まかな説明をしてきましたが、本節では実際にプログラムを書いてみましょう。Word2Vec で単語ベクトルを得るために最低限必要なものは次の二つです。
- テキストデータ(コーパス)
- 学習アルゴリズムを記述したプログラム
ここではコーパスとして Brown Corpus (ブラウン大学による英語のコーパスです)を使ってみます。
学習アルゴリズムの記述は、例えば Gensim (https://radimrehurek.com/gensim/) という Python ライブラリを用いて非常に簡単に記述することができます。
ではさっそくはじめましょう。初めに準備として、NLTK と Gensim という二つのライブラリがインストールされている必要があります(NLTK は Brown Corpus をダウンロードするために使います)。
pip install nltk==3.8.1
pip install gensim==4.3.1
はじめにGensimをインポートします。
import gensim
次に、NLTK を使って Brown Corpus をダウンロードします。
import nltk
nltk.download('brown')
from nltk.corpus import brown
これでコーパスが準備できました。確認のために、brown にどのようなデータが格納されているか見てみましょう。
brown.sents()
[['The', 'Fulton', 'County', 'Grand', 'Jury', 'said', 'Friday', 'an', 'investigation', 'of', "Atlanta's", 'recent', 'primary', 'election', 'produced', '``', 'no', 'evidence', "''", 'that', 'any', 'irregularities', 'took', 'place', '.'], ['The', 'jury', 'further', 'said', 'in', 'term-end', 'presentments', 'that', 'the', 'City', 'Executive', 'Committee', ',', 'which', 'had', 'over-all', 'charge', 'of', 'the', 'election', ',', '``', 'deserves', 'the', 'praise', 'and', 'thanks', 'of', 'the', 'City', 'of', 'Atlanta', "''", 'for', 'the', 'manner', 'in', 'which', 'the', 'election', 'was', 'conducted', '.'], ...]
brown.sents() には文のリストが格納されていて、さらに各文は単語のリストで表現されていることがわかります。
通常は brown.sents() から不要な記号(引用符など)を取り除くなどの前処理をしたほうが良いですが、ここでは簡単化のために brown.sents() をそのまま使います。
さて、コーパスが準備できたので、ここで学習アルゴリズムを実行し、単語ベクトルを作りましょう。たった一行のコードで試すことができます。
# vector_size=100で、単語ベクトルの次元数を100に指定しています。
model = gensim.models.Word2Vec(brown.sents(), vector_size=100, seed=0)
これで、Brown Corpus を基にした単語ベクトルを得ることができました。model.wv[単語] というプログラムで、特定の単語に対応づけられたベクトルを確認できます。ここでは先ほど見た “computer” について見てみます。
model.wv["computer"]
array([ 0.05739009, -0.06453406, -0.06388815, -0.03759238, -0.05865946,
0.0096721 , 0.02258235, -0.0675578 , 0.09179491, 0.09586111,
0.014344 , 0.0846983 , 0.00836285, -0.00502788, 0.03021842,
0.0405383 , 0.08708386, -0.14274324, -0.02961681, 0.00453076,
-0.00086594, 0.10037187, 0.03498571, -0.02217503, 0.12919176,
0.03629847, -0.01707926, -0.020409 , 0.03972119, -0.06014401,
-0.01770747, -0.04424081, 0.05998945, -0.00801145, -0.17684323,
-0.02215051, 0.04967978, 0.01500228, 0.0693899 , -0.05819591,
0.03805631, -0.08456483, -0.07840016, -0.07809567, -0.09568404,
-0.0585987 , -0.00179102, -0.06777907, -0.04078471, 0.06521385,
-0.11314978, -0.00454976, -0.00711755, 0.21795532, 0.08411375,
-0.08447603, 0.0081571 , 0.02782786, 0.00236197, 0.00510744,
-0.03113372, 0.10591434, 0.05540366, -0.04588296, 0.10481917,
-0.03468612, -0.07890923, 0.03575749, 0.02094368, -0.03744064,
-0.08422643, 0.03824924, -0.01526876, 0.04099081, 0.04003001,
0.09236171, 0.0127097 , 0.04056392, -0.01858087, 0.03184031,
0.11627903, -0.06644861, 0.00223213, -0.12401951, 0.07426389,
0.00543479, 0.06010126, -0.02845741, -0.00956686, 0.0773826 ,
-0.02996989, 0.01986621, -0.01758266, -0.11312348, -0.0276615 ,
0.12748377, -0.04607485, -0.05638533, 0.03756217, 0.06013273],
dtype=float32)
このように、各単語は 100 個の数値からなるベクトルで表現されます。これが単語のベクトル表現です。それぞれの数値が何を意味しているか、人間が理解することは困難ですが、数値ベースで表現することにより機械学習アルゴリズムの入力として用いることができるなどの利点があります。
最後に、類似度の高い単語をリストアップしてみましょう。model.wv.most_similar(単語, topn=N) を実行することで、ある単語と最も類似した N 個の単語をリストアップできます。
model.wv.most_similar('computer', topn=10)
[('tool', 0.9595876336097717),
('cylindrical', 0.9577683210372925),
('permanent', 0.9553755521774292),
('cooled', 0.9551491141319275),
('resonance', 0.9528049230575562),
('unfortunate', 0.9515959620475769),
('missile', 0.9507801532745361),
('temporary', 0.9485753774642944),
('package', 0.9474676251411438),
('momentum', 0.9474568963050842)]
いまいち類似しているのかよくわからない単語が上位に挙がっていますね。これは、Brown Corpus が作成されたのが 1960 年代であることから、“computer” という単語に関する情報を十分に持っていないという原因が考えられます(実際のところはよく調べなければわかりません)。このように、学習によって得た単語ベクトルの品質は、学習に用いるデータに依存します。
別の例として “social” と類似度の高い単語を調べてみると、“computer” の場合よりは納得感のある結果が得られます。
model.wv.most_similar('social', topn=10)
[('economic', 0.9477308392524719),
('development', 0.923390805721283),
('political', 0.9074203968048096),
('military', 0.8952915072441101),
('religious', 0.867236852645874),
('community', 0.8666145205497742),
('industrial', 0.8654935956001282),
('national', 0.86518394947052),
('values', 0.8584854006767273),
('local', 0.8562930226325989)]
最後に
この記事では Word2Vec の概要について解説しました。今回のまとめです:
- Word2Vec は、ニューラルネットワークの学習を通じて単語ベクトルを獲得する技術である
- 単語をベクトルで表現することで、類似度計算や、機械学習の適用に繋げることができる
- ベクトル表現の品質は、学習に用いるコーパスに依存する
この記事では書ききれていないこともたくさんあります。ここ数年、単語だけでなく文字や文章、さらには音楽のコードなど、さまざまな対象のベクトル表現が試みられています(Char2Vec、Doc2Vec、Chord2Vec etc.)。
また、ベクトル以外で表現する手法も検討されており、特に最近では Box Embedding が話題になっています。これらのアイデアは、この記事で紹介しきれていない「ベクトルであるがゆえの問題」に動機づけられています。
今回は大まかなイメージを持つことを目指していたので、より踏み込んだ話題についてはまた別の機会に譲りたいと思います。この記事を読んで、Word2Vec や単語のベクトル表現に対するイメージがより具体的なものになっていると嬉しいです。






まずは無料で学びたい方・最速で学びたい方へ
まずは無料で学びたい方: Python&機械学習入門コースがおすすめ

AI・機械学習を学び始めるならまずはここから!経産省の Web サイトでも紹介されているわかりやすいと評判の Python&機械学習入門コースが無料で受けられます!
さらにステップアップした脱ブラックボックスコースや、IT パスポートをはじめとした資格取得を目指すコースもなんと無料です!
最速で学びたい方:キカガクの長期コースがおすすめ

続々と転職・キャリアアップに成功中!受講生ファーストのサポートが人気のポイントです!
AI・機械学習・データサイエンスといえばキカガク!
非常に需要が高まっている最先端スキルを「今のうちに」習得しませんか?
無料説明会を週 2 開催しています。毎月受講生の定員がございますので確認はお早めに!
- 国も企業も育成に力を入れている先端 IT 人材とは
- キカガクの研修実績
- 長期コースでの学び方、できるようになること
- 料金・給付金について
- 質疑応答
DX を推進する AI ・データサイエンス人材育成コース
プログラミング未経験から、AI やデータサイエンスを学ぶことのできる 6 ヶ月間のコースです。転職実績も豊富で、自走できる AI人材を多く輩出しています。

