

こんにちは!機械学習の講師をしている高良です。
業務で Excel を使っているという方は多いと思います。Python と連携することでさらに効率よく Excel を使うことができます!
- Python と Excel で何ができるのか
- 実際にどのような使い方ができるのか
- Python と Excel を連携するメリットとは
といったところや Excel ファイルと Python を連携して操作する方法を解説します!

無料!Python & 機械学習入門コース
キカガク Learning なら「本当に無料?」と驚かれる、Python & 機械学習入門コースを動画とテキストで学べます!AI・機械学習を学び始めてみませんか?
Python と Excel を連携してできること
環境に依存せず自動化できる
Excel と Python を連携するメリットとして Windows や Mac といった環境に左右されにくいことです。
Windows の Excel で動作するマクロが Mac の Excel では動作しないといったことがあります。Python を使えばこういった環境に依存せず Windows, Mac のどちらでも自動化をすることができます。
Python で Excel と他のアプリケーションを連携できる
Python はいろいろなアプリケーションと連携でき、効率よく業務の自動化ができます。
Python を Excel と他のアプリケーションの橋渡しとして使用することで、より業務の自動化に役立てることができます。
Python の基礎を学ぶことができる
Python は使ったことがないけれど Excel なら使ったことがある。そんな方は多いと思います。普段から身近な Excel と合わせて Python を学ぶことで、より円滑に Python の基礎を学ぶことができます。
実行環境
- Google Colaboratory(略称: Google Colab)
- Python:3.7.13
Excel を操作するための準備
- Google Colab の新しいノートブックを立ち上げる
- Google Colab と Google ドライブと接続しておく
Google Colab と Google ドライブは以下のコマンドで接続できます。
from google.colab import drive
drive.mount('/content/drive')Google ドライブとの接続について詳しくはこちらの記事をご覧ください!

OpenPyXL を使う方法
ライブラリのインポート
Google Colab では OpenPyXL が最初からインストールされています。
以下のコマンドで OpenPyXL をインポートします。OpenPyXL は慣例的に op という別名をつけてよく使います。
import openpyxl as opExcelファイルの新規作成
今回は Google ドライブのトップに Excel ファイルを作成してみましょう。
Excel ファイルを新規作成して保存するところまでやってみます。
# Excel ファイル(ワークブック)の新規作成
wb = op.Workbook()
# ワークシートの有効化
ws = wb.active
# Excel ファイルを Google ドライブに保存
# Google ドライブ上の "/content/drive/MyDrive" ディレクトリに "python-excel.xlsx" というファイルが作成される
wb.save("/content/drive/MyDrive/python-excel.xlsx")以上を実行することで Google ドライブのトップに Excel ファイルが作成されます。

Excel ファイルへの書き込み
Excel ファイルの A1 セルにテキストを書き込んでみます。
# A1 セルにテキストを書き込み
ws["A1"] = "Hello!!"
# 保存
wb.save("/content/drive/MyDrive/python-excel.xlsx")上記のコードを実行することで A1 セルに Hello というテキストを書き込むことができます。
試しに Google ドライブから Excel ファイルを開いてみましょう。
このように表示されていれば OK です。
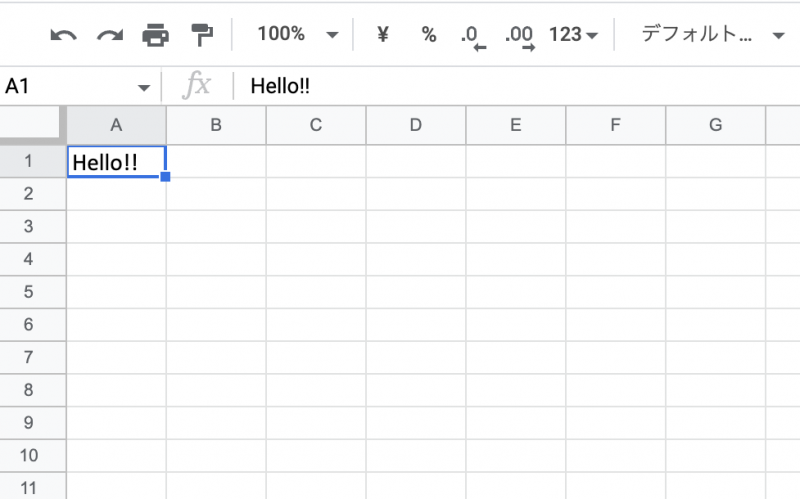
Excel ファイルの読み込み
今回は既に Excel ファイルを開いている状態ですが、新しく Google colab を立ち上げて Excel ファイルを読み込む時は以下のようにします。
# Excel ファイル(ワークブック)の読み込み
wb = op.load_workbook("/content/drive/MyDrive/python-excel.xlsx")
# ワークシートの有効化
ws = wb.active次にセルの内容を読み込みます。
先ほど A1 セルに入力した内容を Google colab 上で表示します。
# value という変数に A1 セルの内容を格納
value = ws["A1"].value
print(value)Hello!!Excel の関数を使う
Excel 関数を入力する場合は =sum(A1:A3) といったようにそのまま入力することができます。
先ほどの Excel ファイルの B1~B3 セルに数字を書き込み、B4 セルに関数を書き込んでみましょう。
# B 列に数字を入力する
ws["B1"] = 1
ws["B2"] = 2
ws["B3"] = 3
# 書き込めているか確認
print(ws["B1"].value)
print(ws["B2"].value)
print(ws["B3"].value)1
2
3# B4 セルに関数を書き込み
ws["B4"] = "=sum(B1:B3)"
# 保存
wb.save("/content/drive/MyDrive/python-excel.xlsx")Excel を開くと SUM 関数によって B4 セルに合計値が表示されていることがわかります。
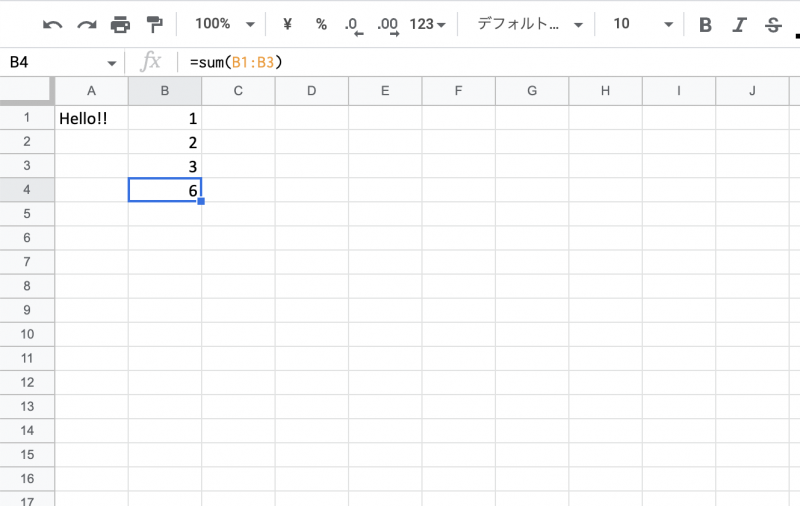
このように OpenPyXL を使うことで Excel ファイルへの書き込みや読み込みが簡単にできます。
ここに Python での for 文や if 文などと組み合わせることで高度なことができるようになります!
ぜひ試してみてください!
Pandas を使う方法
では次は Pandas を使って Excel ファイルを操作する方法をご紹介します。
先ほどは OpenPyXL で Excel ファイルを操作する方法をご紹介しましたが、データ分析などをする場合 Pandas のほうが得意としていることが多くなっています。
OpenPyXL でコードによる Excel の操作に慣れてきたら次はぜひ Pandas での Excel 操作にチャレンジしてみましょう!
Excel ファイルの書き込み
では先ほどと同じように Pandas で Excel ファイルの作成から書き込みの練習をしてみましょう。
まずは Pandas をインポートしてデータフレームを定義します。
import pandas as pd
# データフレームを定義
df = pd.DataFrame([[78, 65, 81],
[91, 76, 77],
[97, 79, 84]],
index=['A 君', 'B 君', 'C 君'],
columns=['国語', '数学', '理科'])
# データフレームの確認
print(df)以下のように返ってきます。
国語 数学 理科
A 君 78 65 81
B 君 91 76 77
C 君 97 79 84こちらを Excel ファイルに書き込み保存します。
# データフレームを Excel に書き込み、ファイルを Google ドライブに保存
# Google ドライブ上の "/content/drive/MyDrive" ディレクトリに "python-excel-pandas.xlsx" というファイルが作成される
df.to_excel('/content/drive/MyDrive/python-excel-pandas.xlsx')Excel ファイルを開き以下のようになっていれば OK です!
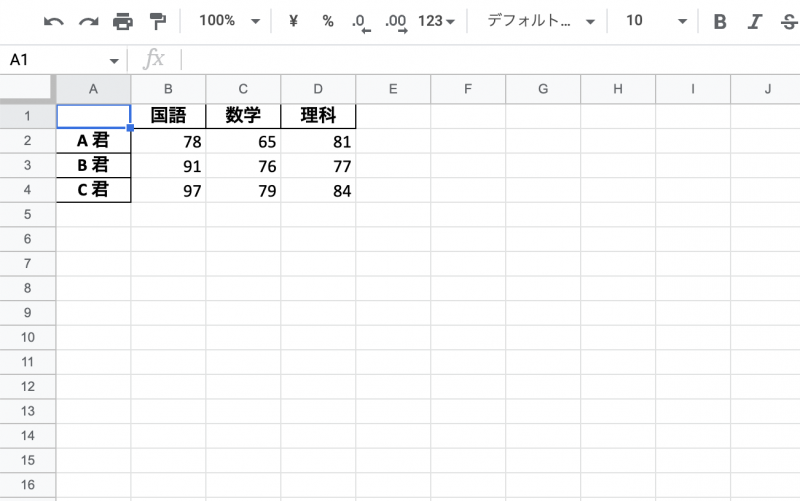
Excel ファイルの読み込み
Pandas での Excel ファイルの読み込み方は以下です。
# Excel ファイルを読み込んで df_read という変数に格納
df_read = pd.read_excel('/content/drive/MyDrive/python-excel-pandas.xlsx')
df_readデータフレームとし読み込むことができ、このように返ってきます。
Unnamed: 0 国語 数学 理科
0 A 君 78 65 81
1 B 君 91 76 77
2 C 君 97 79 84引数早見表
pd.read_excel() を使用する際の引数の早見表です。
詳細は以降の内容で記述します。
| 内容 | 使用例 |
| シートの指定 | sheet_name='シート名' |
| ヘッダーの指定 | header=行番号 |
| ヘッダー名の指定 | names=['列名1', '列名2'] |
| インデックスの指定 | index_col='列名' |
| 読み込む列の指定 | usecols=列番号 |
| 読み込まない行の指定 | skiprows=行番号 |
シートを指定して読み込む
シート番号やシート名の指定ができます。
import pandas as pd
# デフォルト -> 1 つ目のシートを読み込み
df = pd.read_excel('sample.xlsx', sheet_name=0)
# シート番号を指定 -> 3 つ目のシートを読み込み
df = pd.read_excel('sample.xlsx', sheet_name=2)
# シート名を指定
df = pd.read_excel('sample.xlsx', sheet_name='シート名 1')ヘッダー行を指定して読み込む
ヘッダーの指定は header で設定します。
指定した行より上は読み込まれません。
ヘッダー行の番号を指定
行番号の指定を行います。
import pandas as pd
# デフォルト -> 1 行目をヘッダーとして読み込み
df = pd.read_excel('/content/drive/MyDrive/python-excel-pandas.xlsx', header=0)
# 行番号を指定 -> 3 行目をヘッダーとして読み込み
df = pd.read_excel('/content/drive/MyDrive/python-excel-pandas.xlsx', header=2)
# ヘッダーなし -> 1 行目からデータとして読み込み
df = pd.read_excel('/content/drive/MyDrive/python-excel-pandas.xlsx', header=None)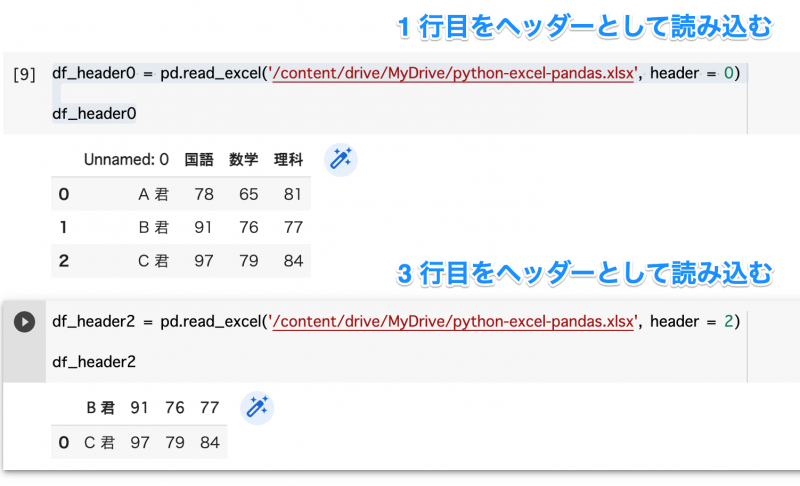
データを絞り込んで読み込む
他にも、読み込む際に便利な引数としてデータを絞って読み込む方法を紹介します。
読み込む列番号を絞り込む
読み込む列を指定したい場合は usecols を設定します。
import pandas as pd
# 読み込む列番号を指定 -> 1,3,4 行目を読み込み
df = pd.read_excel('/content/drive/MyDrive/python-excel-pandas.xlsx', usecols=[0,2,3])
# 読み込む列名を指定 -> B から D 列を読み込み
df = pd.read_excel('/content/drive/MyDrive/python-excel-pandas.xlsx', usecols="B:D")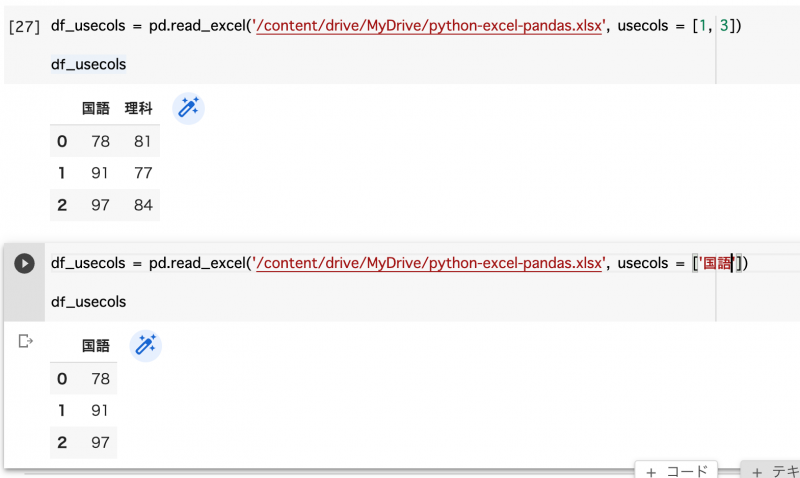
指定した列番号を除外する
読み込まない行を指定したい場合は skiprows もしくは skipfooter を設定します。
import pandas as pd
# 先頭から読み込まない行を指定 -> 先頭 5 行をスキップ
df = pd.read_excel('/content/drive/MyDrive/python-excel-pandas.xlsx', skiprows=5)
# 先頭から読み込まない行をリストで指定 -> 1,3,4 行をスキップ
df = pd.read_excel('/content/drive/MyDrive/python-excel-pandas.xlsx', skiprows=[0,2,3])
# 末尾から読み込まない行を指定 -> 末尾 5 行をスキップ
df = pd.read_excel('/content/drive/MyDrive/python-excel-pandas.xlsx', skipfooter=5)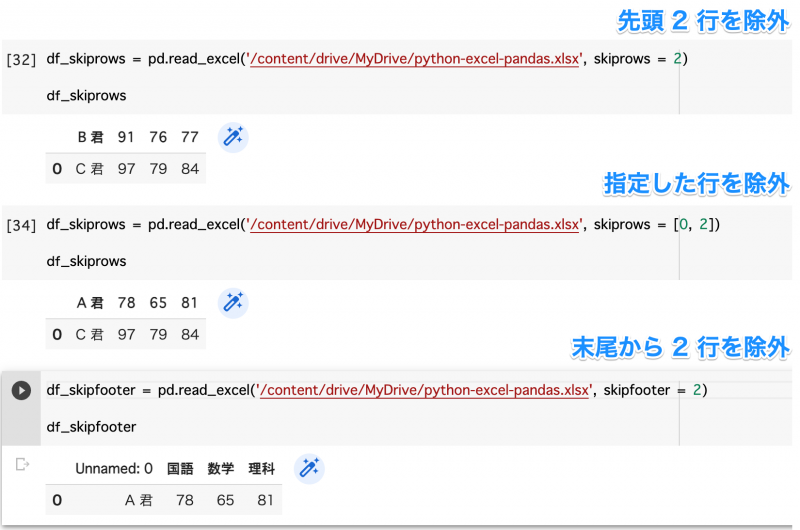
Excel と Python を一緒に学んで効率よくスキルアップしよう!
以上です。本記事では、Python で Excel ファイルを操作する方法を解説しました。
Excel データを操作してデータ分析を行う方々のお力添えになれば幸いです!






まずは無料で学びたい方・最速で学びたい方へ
まずは無料で学びたい方: Python&機械学習入門コースがおすすめ

AI・機械学習を学び始めるならまずはここから!経産省の Web サイトでも紹介されているわかりやすいと評判の Python&機械学習入門コースが無料で受けられます!
さらにステップアップした脱ブラックボックスコースや、IT パスポートをはじめとした資格取得を目指すコースもなんと無料です!
最速で学びたい方:キカガクの長期コースがおすすめ

続々と転職・キャリアアップに成功中!受講生ファーストのサポートが人気のポイントです!
AI・機械学習・データサイエンスといえばキカガク!
非常に需要が高まっている最先端スキルを「今のうちに」習得しませんか?
無料説明会を週 2 開催しています。毎月受講生の定員がございますので確認はお早めに!
- 国も企業も育成に力を入れている先端 IT 人材とは
- キカガクの研修実績
- 長期コースでの学び方、できるようになること
- 料金・給付金について
- 質疑応答
参考リンク
無料!Python & 機械学習入門コース
キカガク Learning なら「本当に無料?」と驚かれる、Python & 機械学習入門コースを動画とテキストで学べます!AI・機械学習を学び始めてみませんか?

