

こんにちは、株式会社キカガクの丸山です。
社内では各種経営数値や、マーケティング関連の数値、収集したアンケート情報、プラットフォーム上のユーザーの行動データ等、様々なデータを Google スプレッドシートを用いて扱っています。
今回は Google スプレッドシートでデータの集計や可視化を行うにあたり、知っていると少し便利な関数をいくつか紹介します。

散らばったデータを 1 箇所に集める IMPORTRANGE
定期的に収集しているアンケート結果が別々のファイルに保存されていたり、チームの各々が独自にファイルを作成しているなどして、散らばって存在しているファイルのデータを一箇所に集めたいケースがあります。
その場合に役に立つのが Importrange 関数です。
importrange 関数は次のように使用します。
IMPORTRANGE(スプレッドシートの URL, 範囲の文字列)参考:IMPORTRANGE – ドキュメント エディタ ヘルプ
例えば、定期的に同内容のアンケート結果を次のように取得している場合を考えてみます。
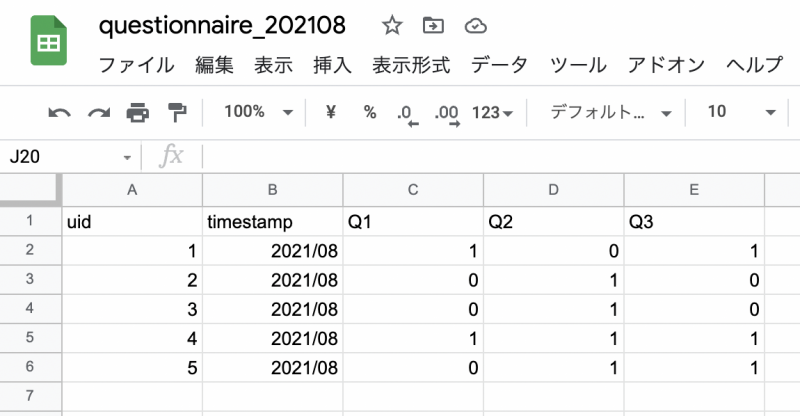
| uid | timestamp | Q1 | Q2 | Q3 |
| 1 | 2021/08 | 1 | 0 | 1 |
| 2 | 2021/08 | 0 | 1 | 0 |
| 3 | 2021/08 | 0 | 1 | 0 |
| 4 | 2021/08 | 1 | 1 | 1 |
| 5 | 2021/08 | 0 | 1 | 1 |
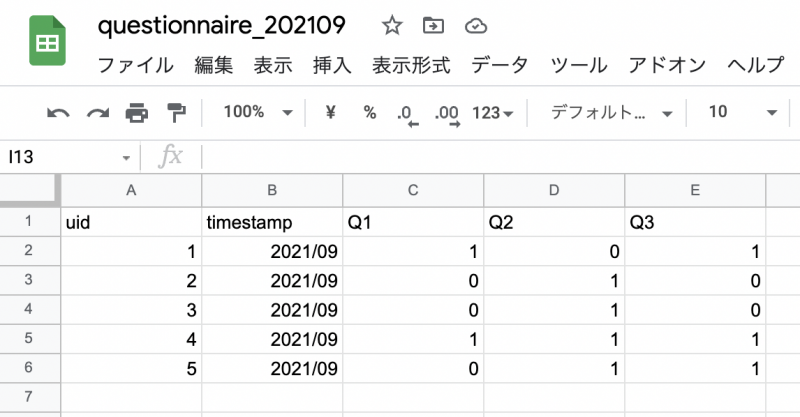
| uid | timestamp | Q1 | Q2 | Q3 |
| 1 | 2021/09 | 1 | 0 | 1 |
| 2 | 2021/09 | 0 | 1 | 0 |
| 3 | 2021/09 | 0 | 1 | 0 |
| 4 | 2021/09 | 1 | 1 | 1 |
| 5 | 2021/09 | 0 | 1 | 1 |
これらのばらばらのファイルを一箇所に集めてみましょう。
新しく GSS ファイルを作成し、次のように A1 セルに記述します。(モザイク箇所は、questionnaire_202108ファイル の URL もしくは ID です。)
=IMPORTRANGE("xxxxxxxxx", "シート1!A1:B6")
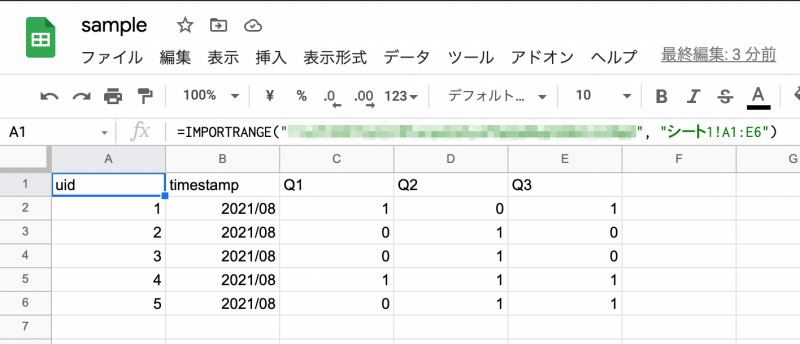
一度シートの接続許可を求められますが、そちらを確認すると上図のように値が反映されると思います。
このようにして複数のファイルを IMPORTRANGE で 1 つのファイルに集めることができます。また、IMPORTRANGE で読み込むデータは横にくっつけたり縦にくっつけたりすることもできます。それぞれ次のように記述します。
- 横の結合:
={IMPORTRANGE(), IMPORTRANGE()} - 縦の結合:
={IMPORTRANGE(); IMPORTRANGE()}
今回の例では、月毎のアンケート回答データで列名が同じであるため、縦に結合して読み込んでみましょう。
={IMPORTRANGE("xxxxxxxxxxx", "シート1!A1:E6"); IMPORTRANGE("xxxxxxxxxxx", "シート1!A2:E6")}
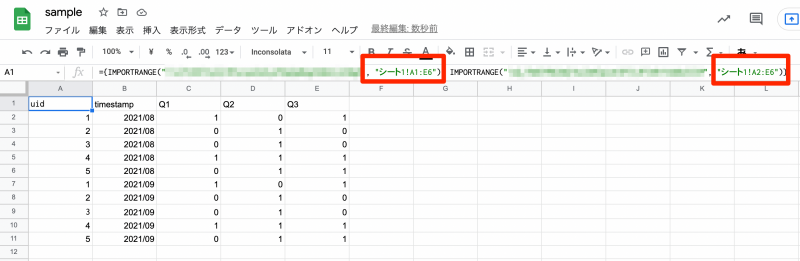
下側にくっつけるテーブルのカラム名が不要な場合は、2 つ目のIMPORTRANGE で与える引数のデータ範囲において、カラム名の行を除くことで上図のような結果を返すことができます。(1 つ目のテーブルは A1:E6、2 つ目のテーブルは A2:E6 の範囲としています。
集計を自動化する QUERY
アドホックに集計をする場合には、ピボットテーブルがやはり大変便利です。ピボットテーブルは直感的に複雑な集計も行いやすいですので基本的にはそちらを使用します。
一方で、ピボットテーブルでは別ファイルのデータソースを参照したい場合には使用できなかったりします。そこで同様のことを関数を用いて行う方法を知っておくと役立つかもしれません。
その際に使用する関数は QUERY です。前述した IMPORTRANGE と組み合わせると、ピボットテーブルでは他シートからデータを読み込んだ生のデータをそのまま残しておいていかなければいけなかったところを、別ファイルをソースとして集計した結果をそのまま表示することができるようになります。また参照範囲内の数値が変化すると集計結果も自動で変わるため便利です。
QUERY 関数は次のような構文で記述します。
QUERY(データ, クエリ, [見出し])具体的にみていきましょう。こちらのデータで gender ごとの平均年齢を算出するには次のように記述します。
| uid | paid | gender | age |
| 1 | 有料 | 男性 | 24 |
| 2 | 無料 | 男性 | 35 |
| 3 | 無料 | 女性 | 26 |
| 4 | 有料 | 男性 | 28 |
| 5 | 有料 | 女性 | 33 |
=QUERY(A1:D6, "SELECT C, AVG(D) GROUP BY C", 1)
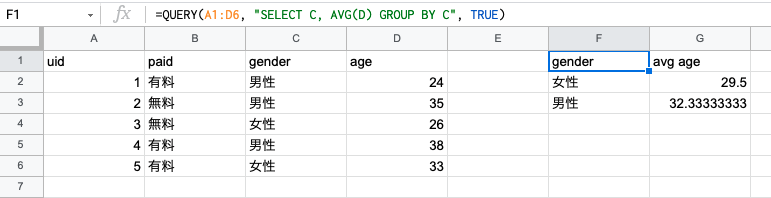
そうすると入力した箇所は F1 セルだけですが、F1 ~ G3 セルに自動で集計表が作成されました。QUERY の引数のクエリには、SQLに近いイメージでどんなデータを出したいか記述します。例えば SELECT 句でどの列の情報を表示したいか選択し、GROUP BY 句でどの列の情報でまとめるかどうかを指定します。今回で言えば、「C 列(gender) ごとに、C 列と D 列平均を表示してください」という意味になります。
クロス集計を行う際には、PIVOT 句を使用します。gender と paid でクロス集計を行ってみましょう。
=QUERY(A1:D6, "SELECT C, AVG(D) GROUP BY C PIVOT B")
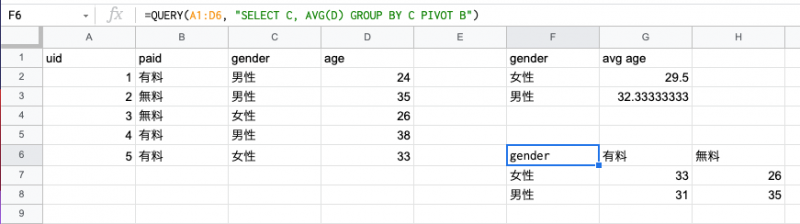
先ほどのクエリに PIVOT B をつけることで、gender ごとかつ paid ごとの平均年齢、という形の集計表を作成することができました。
では最後に IMPORTRANGE と組み合わせて、クロス集計結果だけを別ファイルに表示を行ってみます。この際、列名を指定する際に Col1 や Col2 といったように “Col” + “何番目かの数字” で行う点に注意してください。(何番目か、は 0 はじまりでなく 1 始まりで数えます。)
=QUERY(IMPORTRANGE("xxxxxxxxxx", "シート1!A1:D6"), "SELECT Col3, AVG(Col4) GROUP BY Col3 PIVOT Col2")
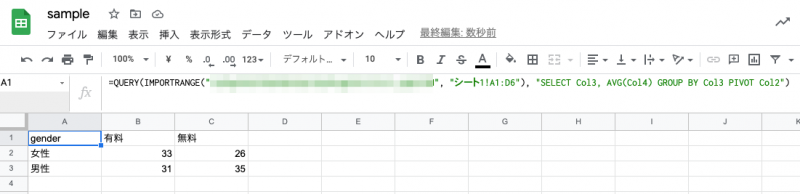
このように別シートのデータを対象に集計結果のみ表示することができました。クエリで指定できる句には WHERE 等、他にもさまざまありますので興味がある方はドキュメントを見てみてください。
可視化の選択肢を増やす SPARKLINE
最後に可視化に関する Tips です。通常の棒グラフや折れ線グラフに加えて、スパークラインもおすすめです。スパークラインとは次のように 1 つのセルの中に表示するミニグラフです。折れ線グラフや棒グラフを 1 つのセルの中に収めることができます。(下図ではセルを結合して横長の 1 つのセルにして中にグラフを表示しています。)
例えば月次推移でみたい指標が何種類かある場合に、ひとつひとつ折れ線グラフにしているとスペースをとってしまい、また特に大事な折れ線グラフはどれなのかが分かりづらくなったりします。そうした際に、大事な指標だけ折れ線グラフで、残りはスパークラインで、などと使い分けると全体としてスッキリした見た目になります。
SPARKLINE は次のように使用します。
SPARKLINE(データ, [オプション])参考:SPARKLINE – ドキュメント エディタ ヘルプ
データ にはグラフ化するデータ範囲を指定し、オプションではグラフの種類や色、最大値最小値などのオプションを指定します。
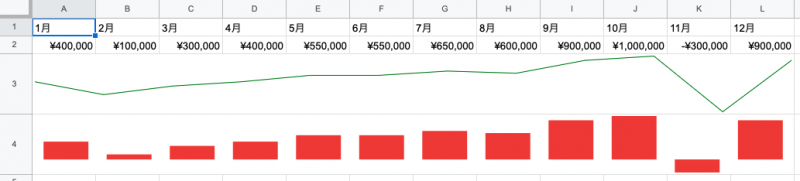
具体的に作成してみましょう。次の内容を貼り付けて、=SPARKLINE(A2:L2, {"charttype","line"; "color", "green"}) と記述してみます。
| 1月 | 2月 | 3月 | 4月 | 5月 | 6月 | 7月 | 8月 | 9月 | 10月 | 11月 | 12月 |
| ¥400,00 | ¥100,00 | ¥300,00 | ¥400,00 | ¥550,00 | ¥550,00 | ¥650,00 | ¥600,00 | ¥900,00 | ¥1,000,00 | -¥300,00 | ¥900,00 |

すると、SPARKLINE を記述したセルの中に小さな折れ線グラフが表示されました。"chartype" のオプションで "line" を指定することで折れ線グラフを意味し、"color" オプションで緑色を指定しています。複数のオプションをつける際には、; で繋ぎます。
"chartype" のオプションでは "line" (折れ線グラフ: デフォルト) 以外にも "bar" (積み重ね棒グラフ), "columns" (縦棒グラフ), "winloss" (正と負の2つの結果を表す棒グラフ) の合計 4 種類を描くことができます。それぞれの "charttype" ごとに異なるオプションが設定できるようになっています。詳細はドキュメントを確認してみてください。
カラースケール
最後に関数ではないですが、カラースケールも紹介します。
行数や列数の多い集計表があった際にパッと見ても、どこが一番多いのか、あるいは少ないのかといったことはなかなか分かりません。そこで、値の大きさでもって色のグラデーションをつけてやることで視認性が大きく向上します。そういったヒートマップのような可視化を行う際にはカラースケールを使用します。
例えば下図左表のように、時間 x 曜日ごとのユーザー数のデータがあったときに、どの曜日のどの時間帯が最も利用者が多いでしょうか?カラースケールを用いると、下図右表のように可視化することができ、値の大きさの比較が容易になります。
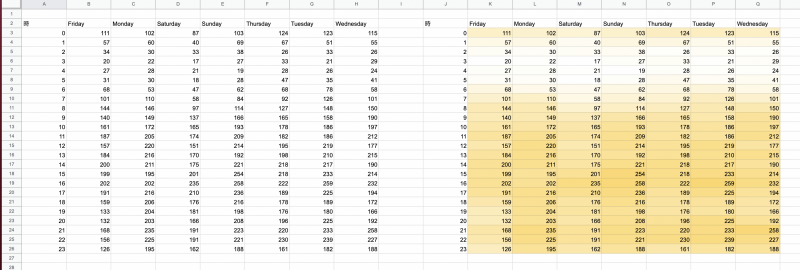
| 時 | Friday | Monday | Saturday | Sunday | Thursday | Tuesday | Wednesday |
| 0 | 111 | 102 | 87 | 103 | 124 | 123 | 115 |
| 1 | 57 | 60 | 40 | 69 | 67 | 51 | 55 |
| 2 | 34 | 30 | 33 | 38 | 26 | 33 | 26 |
| 3 | 20 | 22 | 17 | 27 | 33 | 21 | 29 |
| 4 | 27 | 28 | 21 | 19 | 28 | 26 | 24 |
| 5 | 31 | 30 | 18 | 28 | 47 | 35 | 41 |
| 6 | 68 | 53 | 47 | 62 | 68 | 78 | 58 |
| 7 | 101 | 110 | 58 | 84 | 92 | 126 | 101 |
| 8 | 144 | 146 | 97 | 114 | 127 | 148 | 150 |
| 9 | 140 | 149 | 137 | 166 | 165 | 158 | 190 |
| 10 | 161 | 172 | 165 | 193 | 178 | 186 | 197 |
| 11 | 187 | 205 | 174 | 209 | 182 | 186 | 212 |
| 12 | 157 | 220 | 151 | 214 | 195 | 219 | 177 |
| 13 | 184 | 216 | 170 | 192 | 198 | 210 | 215 |
| 14 | 200 | 211 | 175 | 221 | 218 | 217 | 190 |
| 15 | 199 | 195 | 201 | 254 | 218 | 233 | 214 |
| 16 | 202 | 202 | 235 | 258 | 222 | 259 | 232 |
| 17 | 191 | 216 | 210 | 236 | 189 | 225 | 194 |
| 18 | 159 | 206 | 176 | 216 | 178 | 189 | 172 |
| 19 | 133 | 204 | 181 | 198 | 176 | 180 | 166 |
| 20 | 132 | 203 | 166 | 208 | 196 | 225 | 192 |
| 21 | 168 | 235 | 191 | 223 | 220 | 233 | 258 |
| 22 | 156 | 225 | 191 | 221 | 230 | 239 | 227 |
| 23 | 126 | 195 | 162 | 188 | 161 | 182 | 188 |
目視で探していくのは非常に大変ですが、色の濃淡がついていれば探しやすくなります。ではカラースケールで色をつけてみましょう。
次の手順で進めていきます。
- 色をつけたい範囲を指定する
- 表示形式タブを選択
- 条件付き書式を選択
- 画面右側に出てくるエリアで、「カラースケール」を選択
- 「書式ルール」をクリックし、任意の色を選択
すると次のように色をつけることができました。(白→黄のグラデーションを選択しています。)
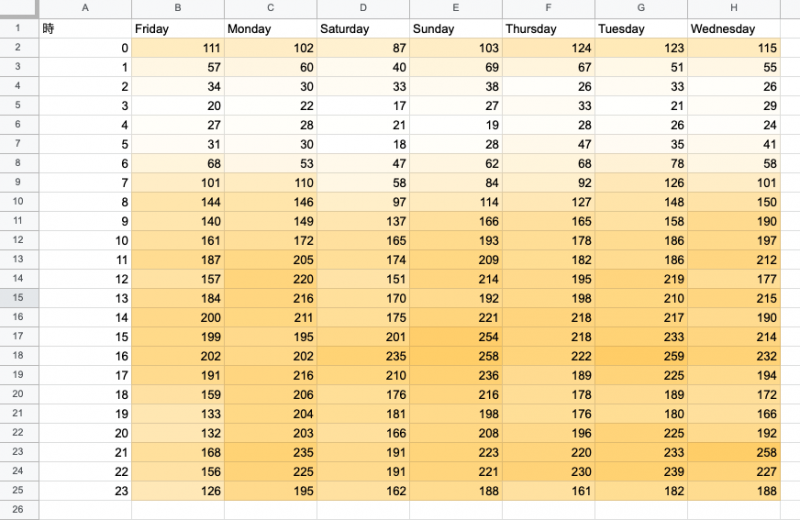
こうして見ると、色の濃い箇所を重点的にみればよいですので、一番ユーザー数が多いのは火曜の16 時代ということが探しやすくなりますね。
まとめ
Googl スプレッドシートで使える関数をいくつか紹介しました。
社内でこれからデータ活用を進める、といった場合には誰もが使い慣れたツールでデータ活用の土壌をつくっていくことがファーストステップとして大事だと思っています。スプレッドシートでもたくさんのことができますので、知らなかったけどこれ便利だな!というものがこの記事の中にあれば嬉しく思います。
最後まで読んでいただきありがとうございました。






まずは無料で学びたい方・最速で学びたい方へ
まずは無料で学びたい方: Python&機械学習入門コースがおすすめ

AI・機械学習を学び始めるならまずはここから!経産省の Web サイトでも紹介されているわかりやすいと評判の Python&機械学習入門コースが無料で受けられます!
さらにステップアップした脱ブラックボックスコースや、IT パスポートをはじめとした資格取得を目指すコースもなんと無料です!
最速で学びたい方:キカガクの長期コースがおすすめ

続々と転職・キャリアアップに成功中!受講生ファーストのサポートが人気のポイントです!
AI・機械学習・データサイエンスといえばキカガク!
非常に需要が高まっている最先端スキルを「今のうちに」習得しませんか?
無料説明会を週 2 開催しています。毎月受講生の定員がございますので確認はお早めに!
- 国も企業も育成に力を入れている先端 IT 人材とは
- キカガクの研修実績
- 長期コースでの学び方、できるようになること
- 料金・給付金について
- 質疑応答

