

キカガク機械学習講師の船蔵颯です!本記事では、深層学習の基盤技術ともいえる Transformer について解説します。
ChatGPT が発表され、言語モデル GPT をベースとしたサービスが非常に身近なものとなってきています。多くの大規模言語モデルがその中核として採用している機構が Transformer です。また、BERT (自然言語処理) や Vision Transformer (画像処理) 、wav2vec 2.0 (音声処理) など、ChatGPT の興隆以前から Transformer は多方面で利用されています。
そのため、Transformer は深層学習の必須知識といえる状況になってきています。本記事では、Transformer の仕組みをポイントを絞ってわかりやすく解説します。

DX を推進する AI ・データサイエンス人材育成コース
プログラミング未経験から、AI やデータサイエンスを学ぶことのできる 6 ヶ月間のコースです。転職実績も豊富で、自走できる AI人材を多く輩出しています。
Transformer による革命
Transformer はニューラルネットワークの一種です。2017 年に提案され、その時点でも大きな注目を集めていました。
Transformer の原型は機械翻訳などの系列変換タスクを想定していましたが、Transformer をベースとした GPT (2018 年)、BERT (2018 年) が提案されたことで、さまざまな言語処理タスクで利用されるようになりました。
さらに、Transformer は自然言語だけでなく、音声や画像にも有効であることが明らかになりました。特に、画像処理での先駆けである ViT (2020 年) はよく知られています。
本記事では、これら派生手法の基礎となっている Transformer について解説していきます。後にご紹介する Hugging Face Transformers をはじめ、Transformer を活用したさまざまなモデルが利用しやすい形で整備されています。こうした中で、これから解説する内容は活用のための必須知識ではないかもしれません。
とはいえ、モデルの計算過程や出力結果を理解し、そして自身の目的に合わせてカスタマイズするためには、ある程度中身を理解しておく必要があります。また、それを差し引いても Transformer は面白いです!
まずは Transformer の原型について解説し、その後に登場した派生モデルを紹介します。
Transformer の概観
本節では Transformer の仕組みを解説します。計算の詳細には立ち入らず、大局的なイメージを掴むことがここでの目標です。より詳しい内容については都度、適切な文献をご紹介します。
Transformer は系列変換のためのニューラルネットワークです。系列とは順序を持った並びのことであり、例えば文は単語の系列とみなすことができます。代表的な系列変換タスクとして、機械翻訳が挙げられます。

その他にも、質問応答(チャットボット)や、文書要約など、系列変換タスクの例としてはさまざまなものがあります。
エンコーダ・デコーダモデル
系列変換のためのニューラルネットワークの多くは、エンコーダ・デコーダから構成されます。Transformer も同様で、次のような構造になっています。
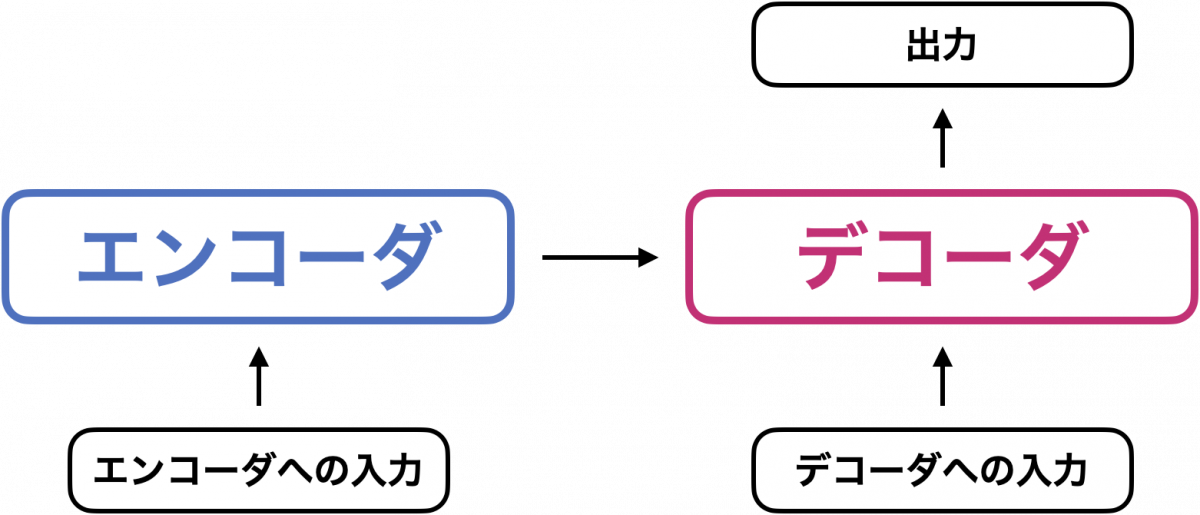
大まかな見方としては、エンコーダは「入力系列の重要な特徴を抽出する」役割を担い、デコーダは「エンコーダが抽出した特徴をもとに、系列を生成する」役割を担います。
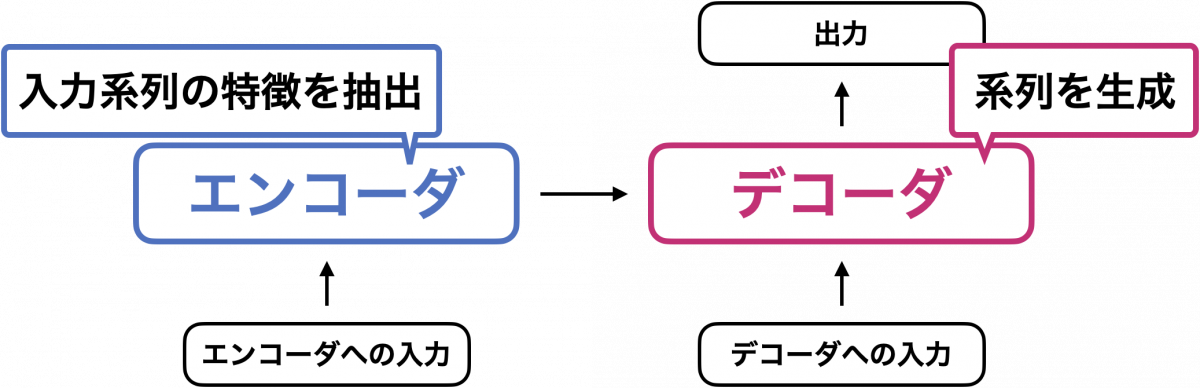
計算過程を少し詳しく追ってみましょう。ここでは上記のモデルを翻訳モデルとみなして、「機械学習はすごく面白い」を英語に翻訳する過程を見てみます。
形態素解析
最初に、入力文「機械学習はすごく面白い。」をトークン (token) と呼ばれる単位に分割します。この手続きは形態素解析 (tokenization) と呼ばれ、自然言語処理モデルではお馴染みの手続きです。形態素解析の手法には様々なものがありますが、ここでは次のように形態素解析されたと仮定します。

埋め込み
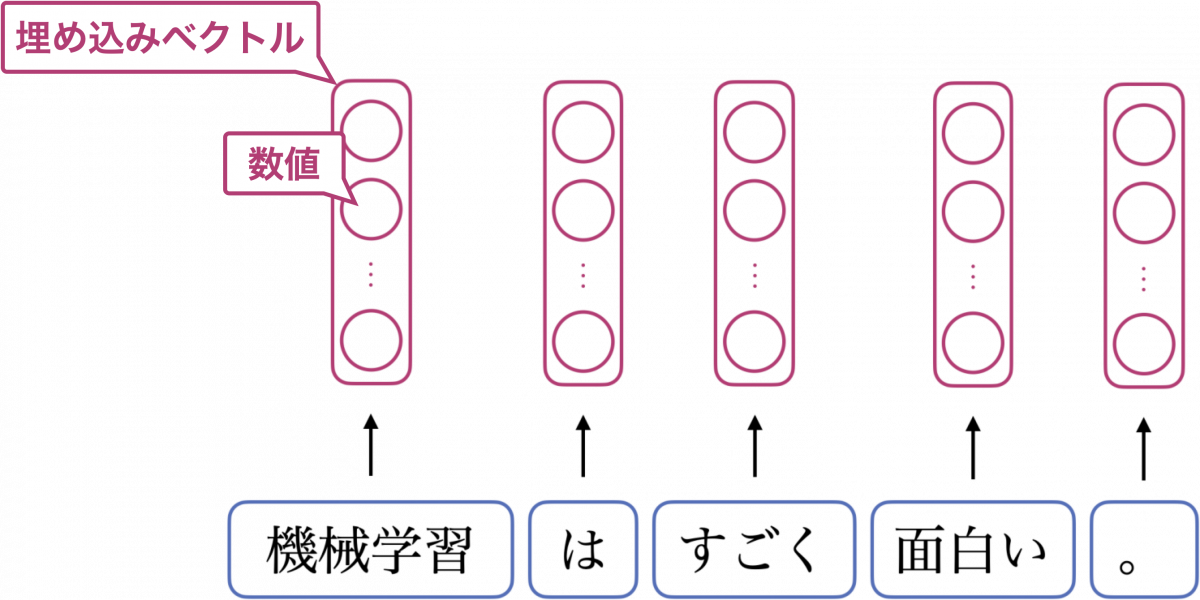
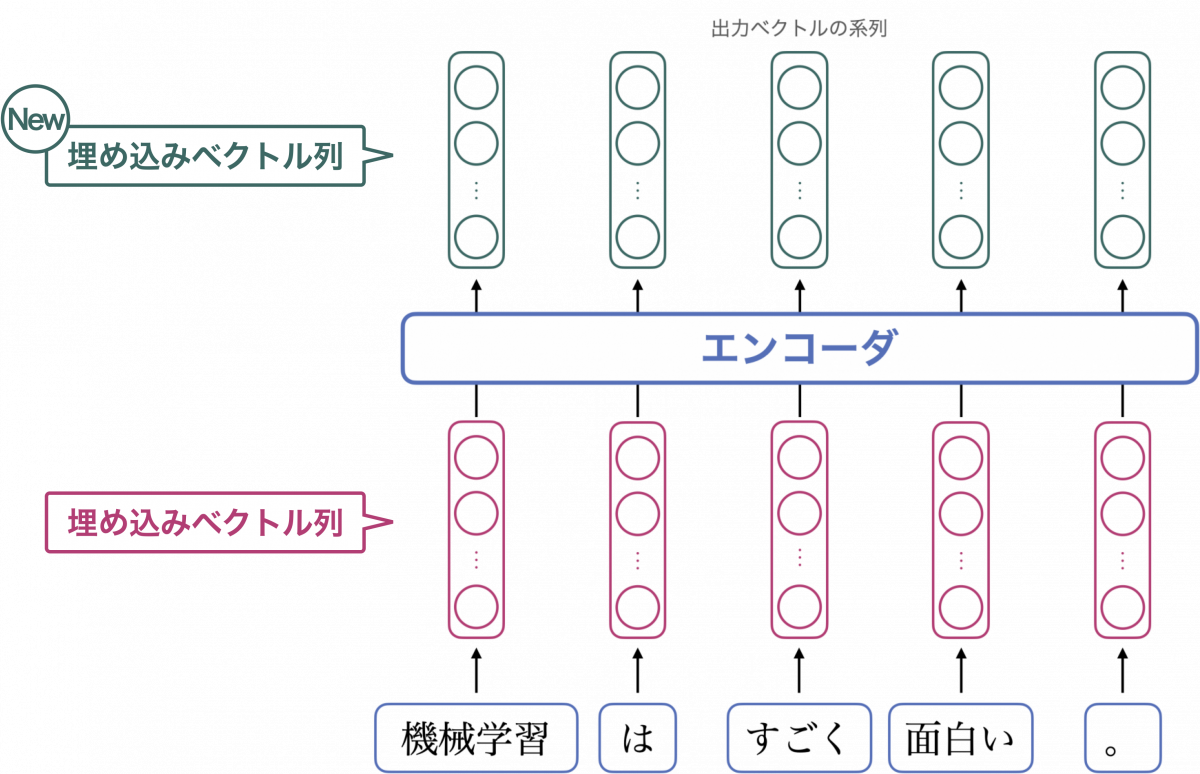
次に、各トークンをベクトルに変換します。変換する手法について深くは立ち入りませんが、変換結果のベクトルのことを埋め込みベクトルと呼びます。系列変換の最初のステップとして、埋め込みベクトルの列をエンコーダに入力します。
各トークンを埋め込みベクトルに変換するイメージを下図に示します。○を数値として見てください。
エンコーダは、ベクトルの列を入力とし、ベクトルの列を出力するニューラルネットワークです。今回のように入力ベクトルが五つの場合は、同じく五つのベクトルが出力され、それらは各トークンの新たな埋め込みベクトルとみなすことができます。
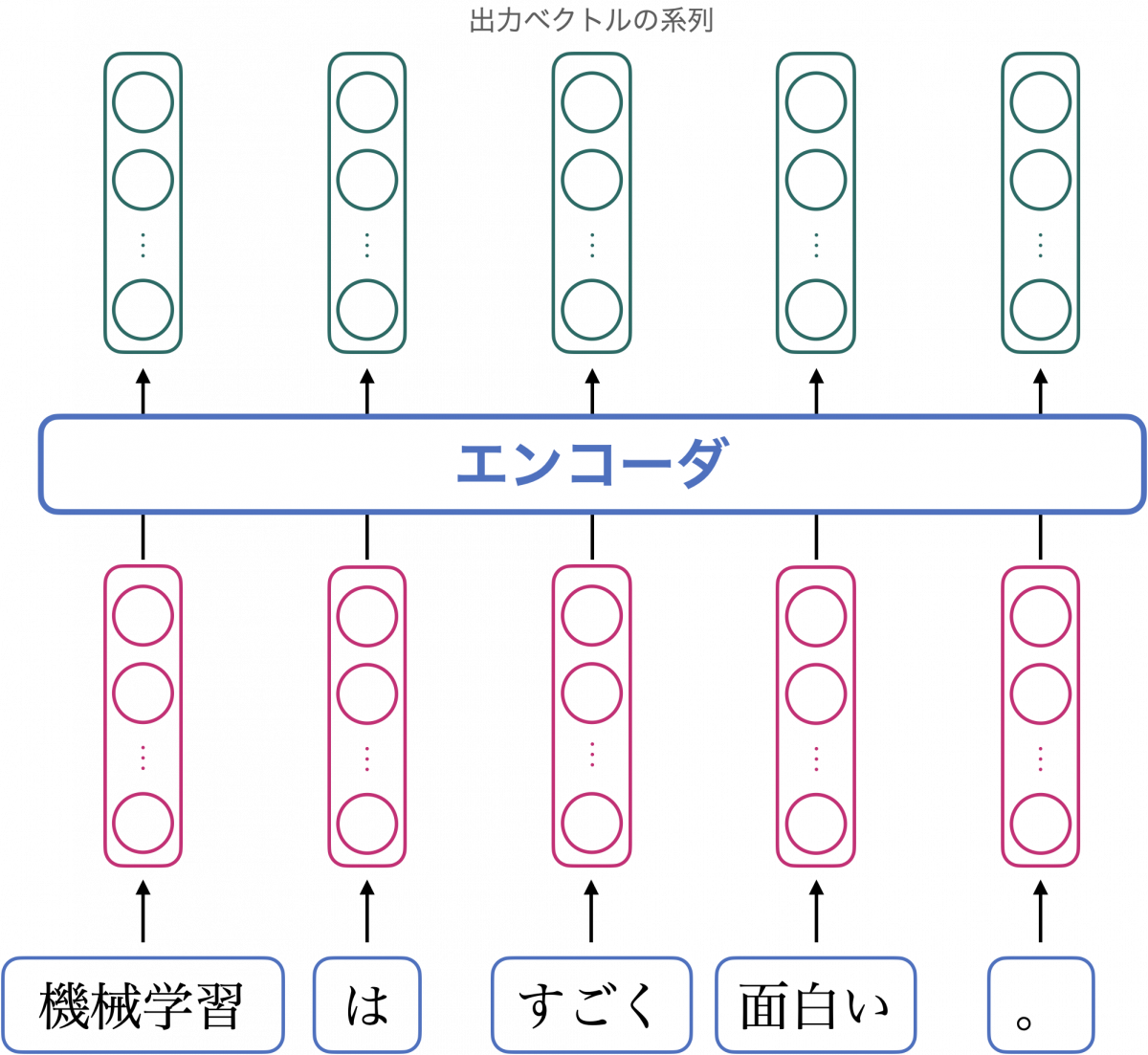
ではこれから、エンコーダが行う計算について見ていきましょう。
エンコーダの仕組み
エンコーダの役割
先ほど述べたように、エンコーダはベクトルの列を入力として、ベクトルの列を出力します。そして、入力のベクトル列が埋め込みベクトルの列である場合、出力のベクトル列も埋め込みベクトルの列と見なすことができます。
では、入力のベクトル列と、出力のベクトル列とでは、何が違うのでしょうか?その答えは、「文脈を考慮しているかどうか」です。
「機械学習」に対応する入力ベクトルは、周辺の単語「は」や「すごく」などと独立に計算されますが、出力ベクトルは、「機械学習」に対応する入力ベクトルだけでなく、すべての入力ベクトルをもとにして計算されます。
より詳しく述べると、「機械学習」に対応する出力ベクトルは、「機械学習」との関連が強い単語をより色濃く反映する形で計算されます。関連の強さは入力ベクトルをもとに自動的に計算されます(後述)。
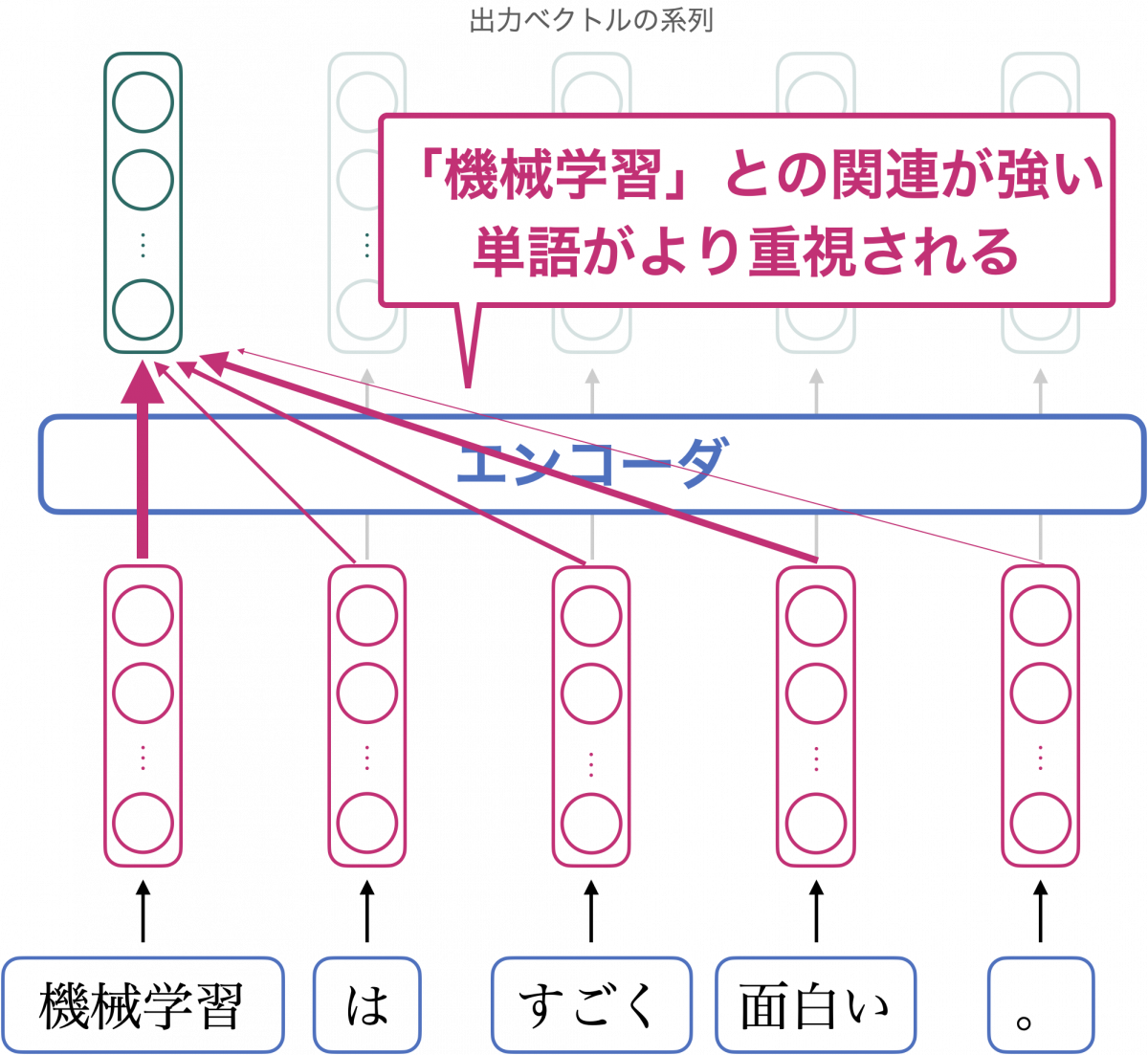
従って、出力ベクトルは「その単語がどのような単語と一緒に出現しているか」という情報、つまり文脈の情報を含んでいます。文脈を考慮する手法自体は Transformer 以前にも提案されていましたが、Transformer はより効率的に計算しやすい形でこれを実現しています。
自己注意機構
それでは、関連度合いをどのようにして計算するかを簡単にご説明します。
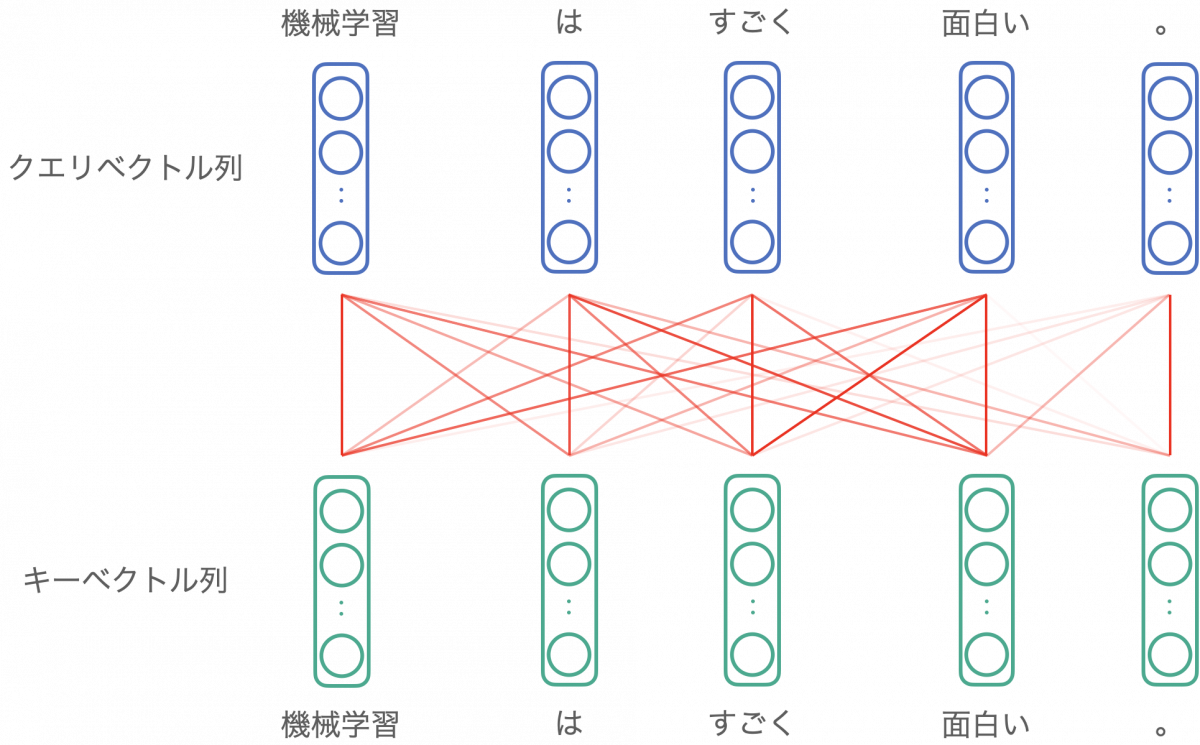
鍵となるのは注意機構 (attention mechanism) です。注意機構とは、二つの系列の間で、各要素の関連度合いを計算する手法です。下図はそのイメージで、三要素からなる二つの系列に対して注意機構を適用した様子を表しています。関連度合いを線の濃さで表現しています。
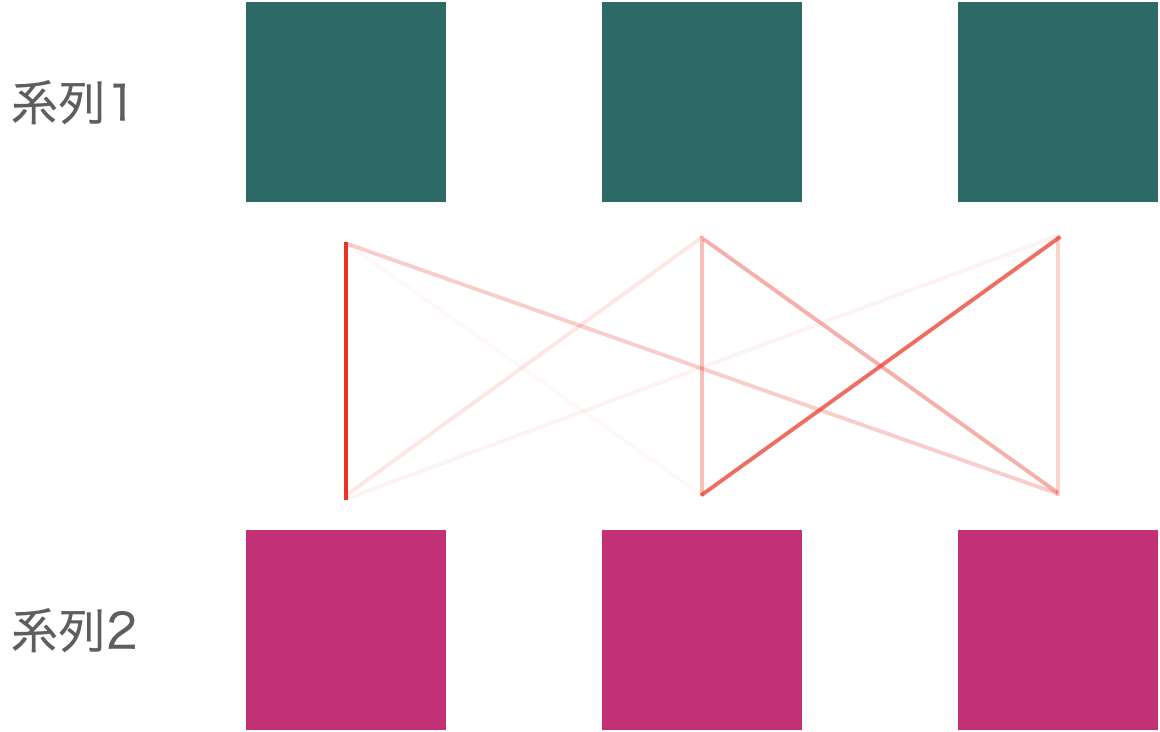
注意機構にはいくつかのバリエーションがあり、Transformer で提案された注意機構は自己注意機構 (self-attention mechanism) と呼ばれます。自己注意機構とは、同じ系列に対して注意機構を適用する手法です。つまり、上図での系列 1 と系列 2 が同じ系列になります。
自己注意機構を「機械学習はすごく面白い。」に適用したときのイメージを下図に示します。
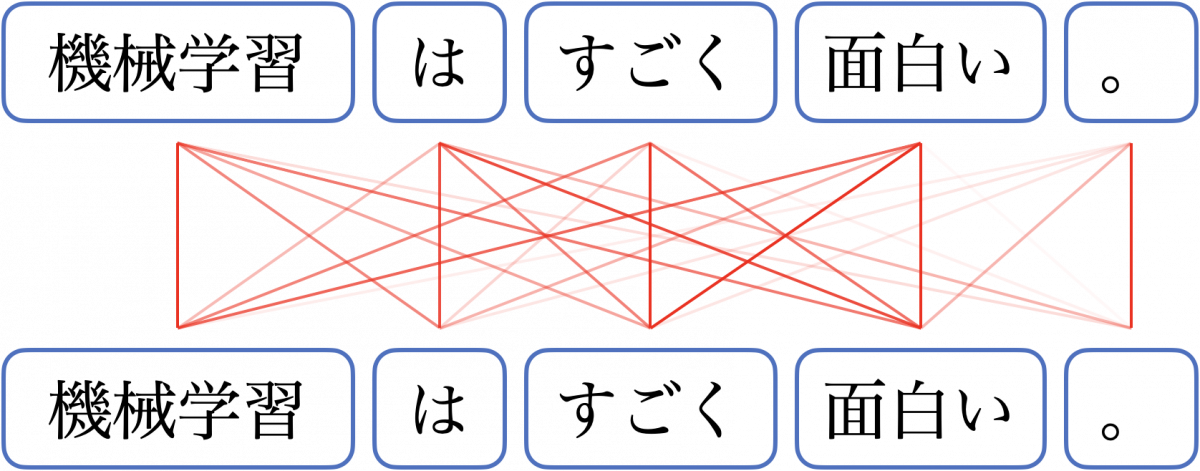
より厳密には、各単語に対応するクエリベクトル列とキーベクトル列に注意機構が適用されています。クエリベクトル・キーベクトルは入力の埋め込みベクトルをもとに計算されますが、詳細は割愛します。
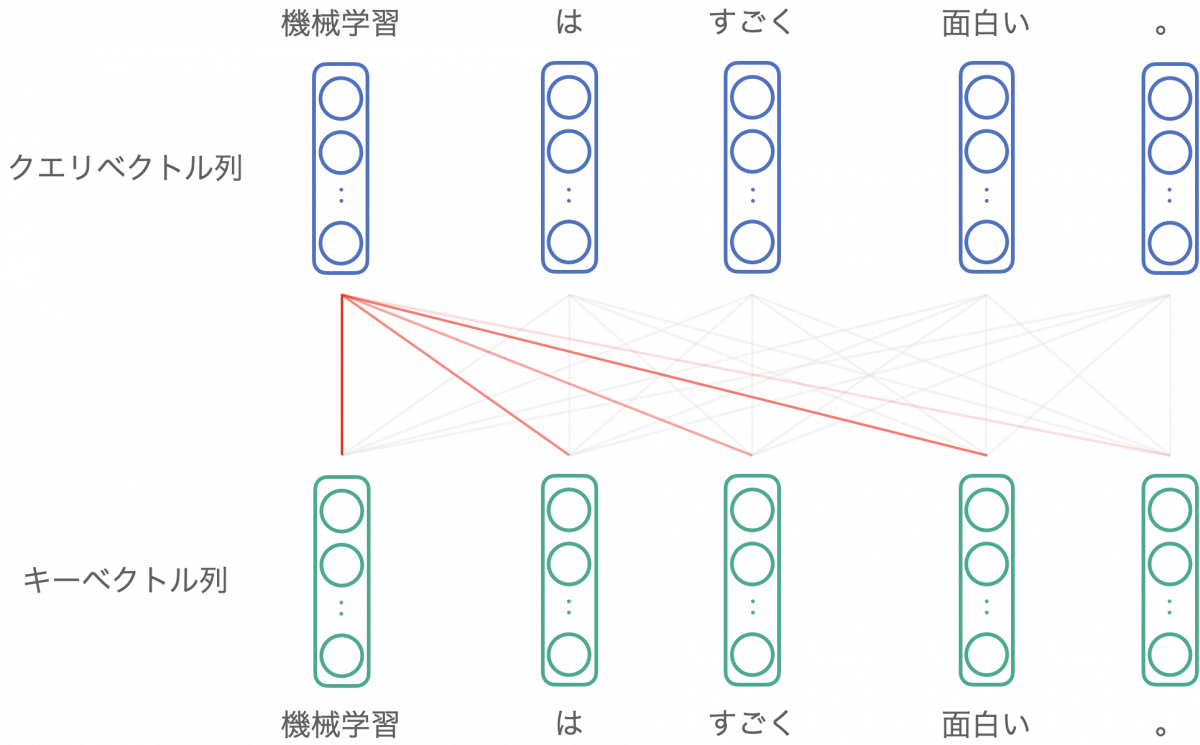
出力ベクトルの計算方法
では、計算された関連度をもとにしてどのように出力ベクトルが計算されるかを見ていきます。
たとえば「機械学習」に対応する出力ベクトルは、「機械学習」クエリベクトルから見た、各キーベクトルとの関連度を反映して計算されます。
重要度は足して 1 になるように計算されます。ここでは以下のような値になったとします。
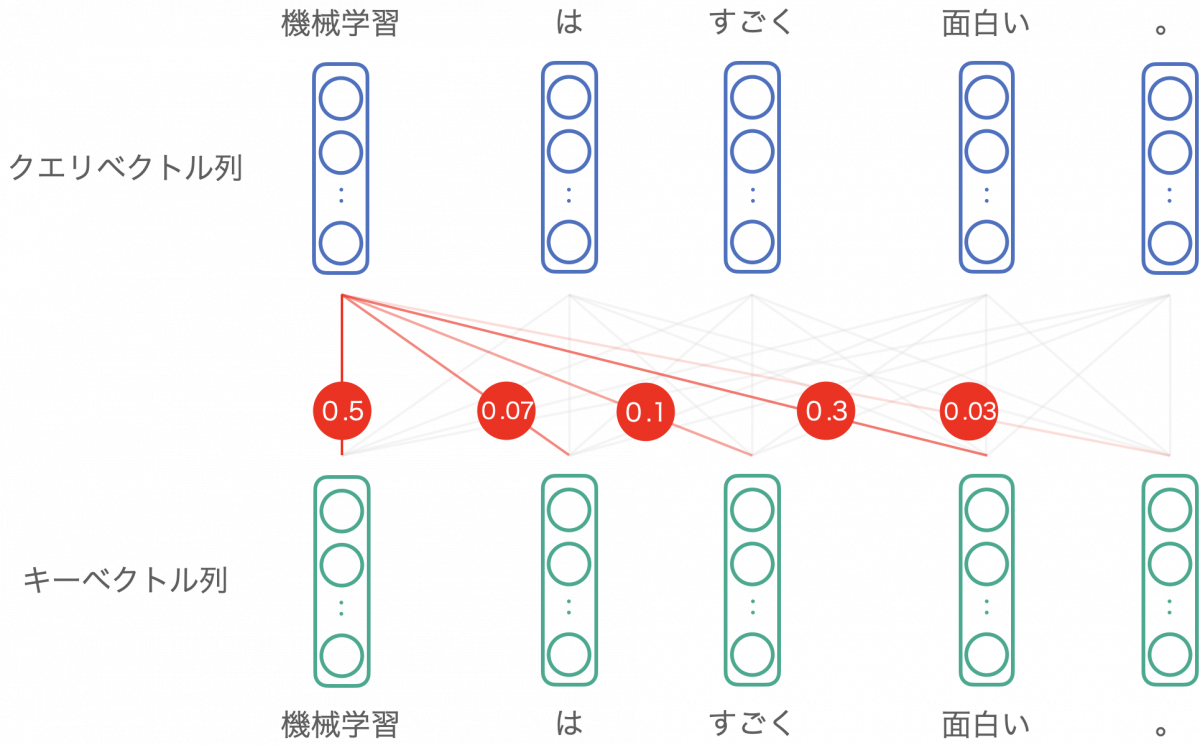
この各関連度を、各単語に対応するバリューベクトルというベクトル列に掛けて、和を取ります。これが、自己注意機構の出力です。
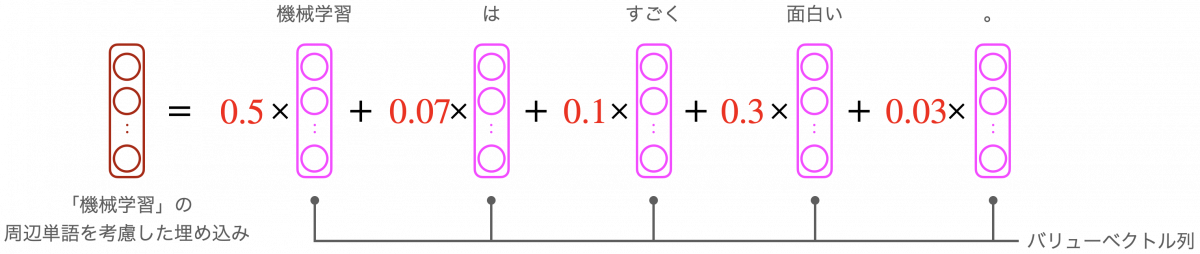
以上の計算により、周辺単語を関連度に応じて反映した、埋め込みベクトルを作ることができます。同様の計算は他の単語についても行われます。つまり、自己注意機構は入力された各単語について、周辺単語を考慮して埋め込みベクトルを計算します。
以上、入力ベクトル列が自己注意機構によって変換される様子を見てきました。ここまでの内容を下図にまとめます。参考として、具体的な計算式を図に記載しています。ご興味があれば Transformer 論文 [Vaswani+ 2017] や、その他 Transformer に関連する文献を参照してください。
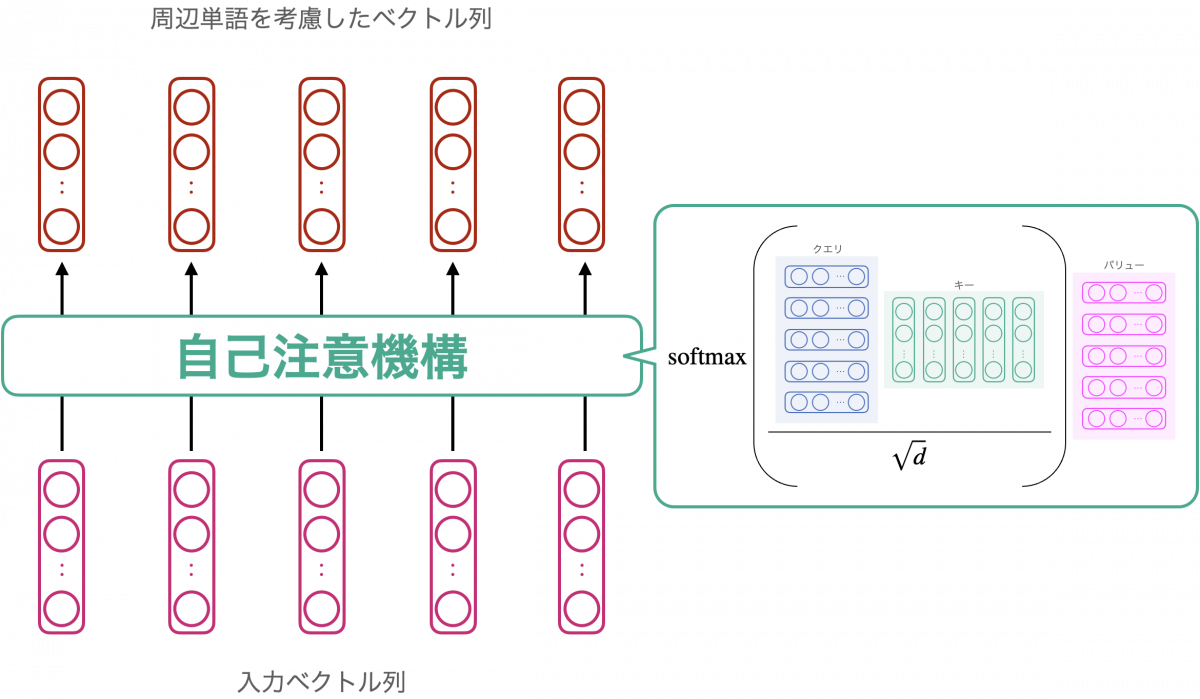
自己注意機構の出力として得られたベクトル列をさらに少し変換することで、エンコーダの出力が得られます。どう変換しているかはここでは割愛しますので、詳しくは他文献を参照ください。
エンコーダまとめ
以上、エンコーダの中核をなす自己注意機構について解説しました。
エンコーダには自己注意機構以外の部品も含まれていますが、本記事で強調したいことは次のメッセージに尽くされています。
エンコーダは、周辺単語を考慮したベクトル列を出力する
エンコーダの入出力イメージを改めて下図に示します。
以上、Transformer を構成するエンコーダの処理について解説しました。エンコーダが出力する埋め込みベクトルは、デコーダへの入力として使います。デコーダは、エンコーダの出力と、自らの出力を用いて系列を生成します。次節では、デコーダの処理について解説します。
- エンコーダを構成する演算としては、自己注意機構の他に残差接続 (skip connection)、層正規化 (layer normalization)、フィードフォワードネットワーク (feed-forward network) が用いられています。
- ここでは単一のエンコーダを仮定していますが、エンコーダは複数連結するのが一般的です。例えば、Transformer の提案論文では 6 つのエンコーダを連結しています。
- Transformer の提案論文を含め、実際には自己注意機構を並列に複数適用し、より多角的な特徴抽出を狙っています。詳しくはマルチヘッド自己注意機構について調べてみてください。
デコーダの仕組み
デコーダの役割
改めて、エンコーダ・デコーダモデルの機構を振り返りましょう。エンコーダは入力された系列を、より文脈を考慮した系列にして出力する、つまり入力系列の特徴を抽出する機構として説明しました。これに対して、デコーダは系列を生成する役割を担います。
本節では、デコーダーが系列を出力する仕組みを解説します。
デコーダが系列を出力する仕組み
機械翻訳の場合の入出力イメージを下図に示します。デコーダ内での具体的な計算は後に述べることにして、まずは系列が出力される仕組みを追っていきましょう。
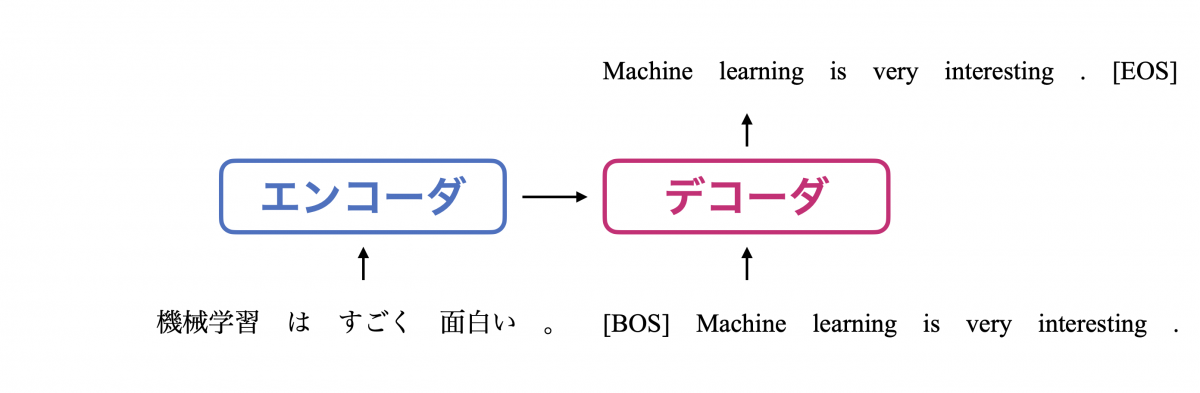

つまり、あるステップで出力されたトークンが、次のステップの入力に追加されていきます。上の図は 3 ステップ目までを示していますが、実際には [EOS] が出力されるか、システムが許容できる長さまで出力が行われた時点で生成が終了します。
- Transformer のデコーダのように、前のステップで自らが出力した結果を次のステップでの入力とするモデルは、自己回帰モデル (auto-regressive model) と呼ばれます。
- 以上はモデルを運用する際の入出力イメージです。学習時にはデコーダの出力にかかわらず、各ステップの入力として学習用データのトークンが順次追加されていきます。
デコーダ内部の計算
デコーダ側も基本的な部品は注意機構です。デコーダがエンコーダと異なるのは、入力系列についての自己注意機構に加えて、入力系列と、エンコーダの出力系列についての注意機構を用いている点にあります。下図にデコーダ機構のイメージを示します。
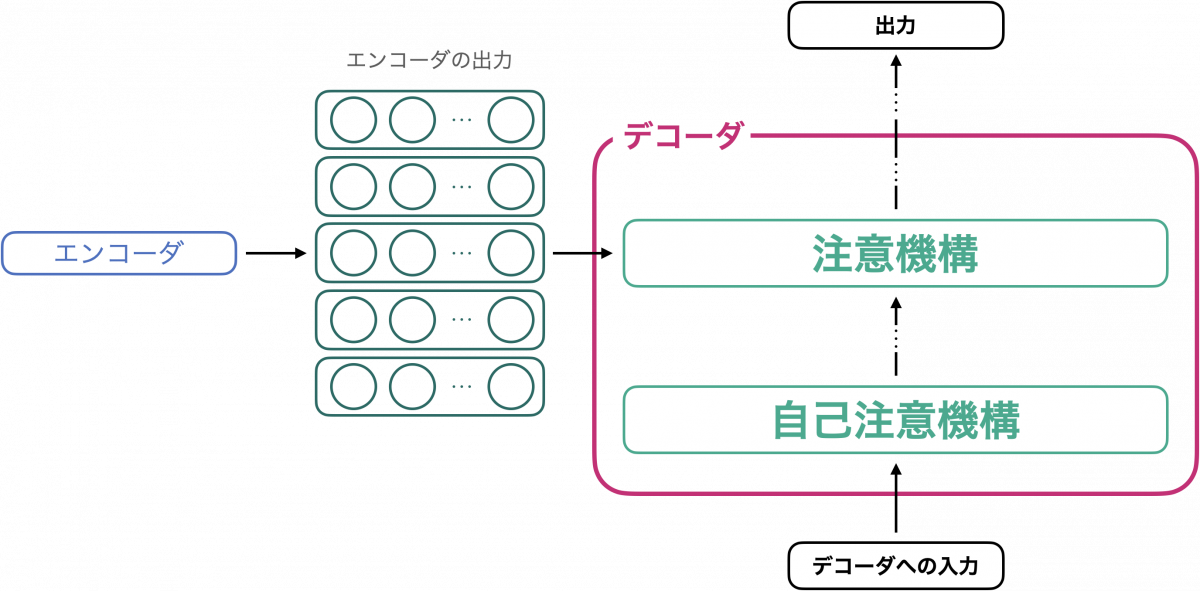
図を見ながら、計算の流れを追ってみましょう。
まず、デコーダへの入力系列(例えば “[BOS] Machine learning” など)に自己注意機構を適用することで、文脈を考慮したベクトル列を作ります。これらのベクトル列が、次の注意機構でのクエリベクトル列として用いられます。キーベクトル、バリューベクトルとしては、エンコーダの出力が使われます。これにより、エンコーダへの入力系列がデコーダに共有されます。
そして、図では省略しているいくつかの処理を通すことで、「単語の確率分布」が出力されます。デコーダが生成する単語列は、この分布をもとに決定されます。先ほどの翻訳の例でのイメージを下に示します。この例の場合であれば、出力された分布を「[BOS] に続く単語は何か」の予測として解釈します。
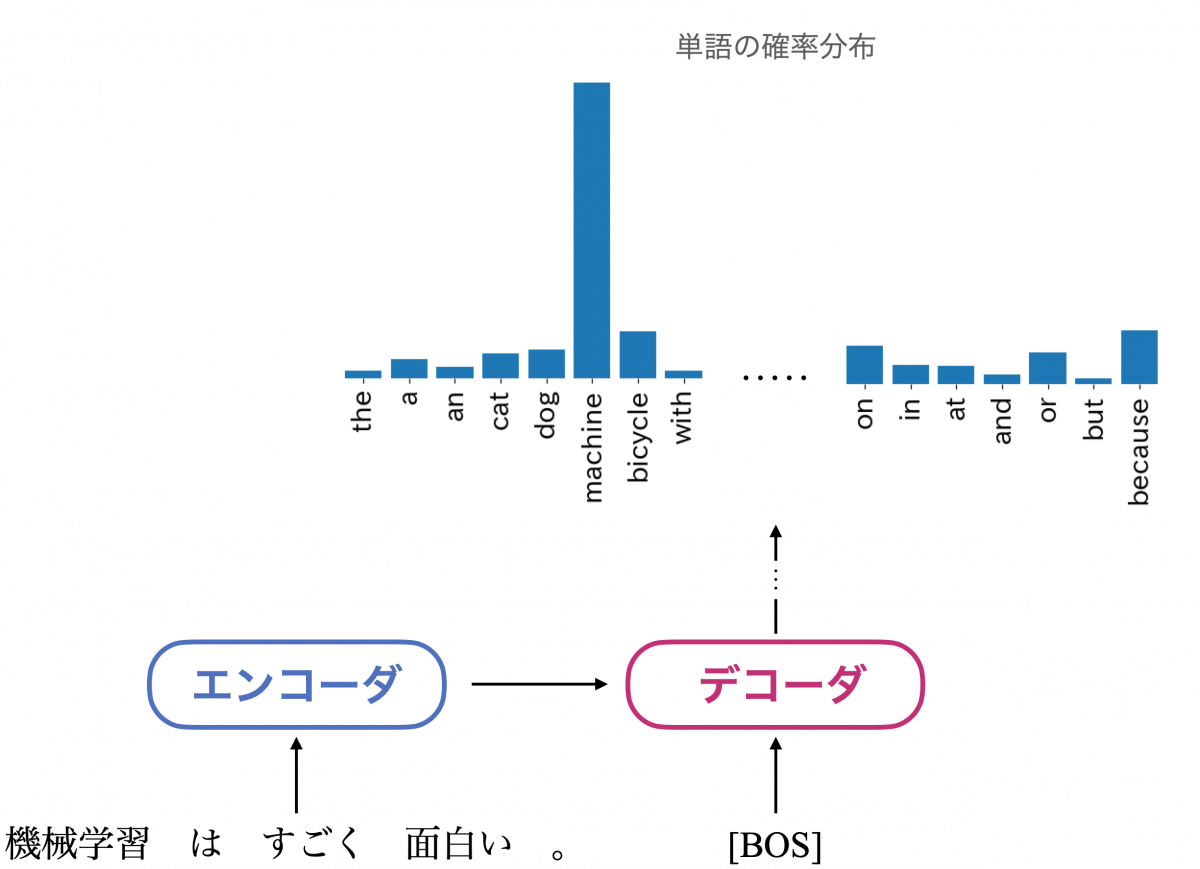
この分布をもとに [BOS] に続く単語を選択し、次のステップの入力に加えます。この処理を繰り返していくことで、系列が生成されます。
出力された確率分布を基にどの単語を生成するか、という選択は実は容易ではありません。素朴な方法である貪欲法 (greedy search) は計算効率の面でやや問題があります。広く用いられているのはビームサーチ (beam search) で、Transformer の提案論文でも採用されています。
デコーダまとめ
以上、デコーダによって系列が生成される仕組みを追ってきました。モデルの構造についてもご説明しましたが、ここで押さえておきたいのは次のポイントです。
デコーダは、エンコーダの出力を基に系列を生成する自己回帰型モデル
自己回帰的に系列生成する過程を下に再掲します。
Transformer まとめ
以上、系列変換モデルとは何かから始まり、エンコーダ、デコーダについて解説してきました。エンコーダ・デコーダそれぞれの役割は下図に示す通りです。
エンコーダ・デコーダそれぞれの中核をなす自己注意機構については、さまざまな改良が提案されています [Child+ 2019, Wang+ 2019, Katharopoulos+ 2020, etc.]。本記事で扱った自己注意機構の基本的な理解は、これらの提案を理解する上で役に立ちます。
Transformer の派生モデルと活用法
本記事の最後に、Transformer の派生モデルとその活用法について解説します。
GPT, BERT: Transformer × ファインチューニング
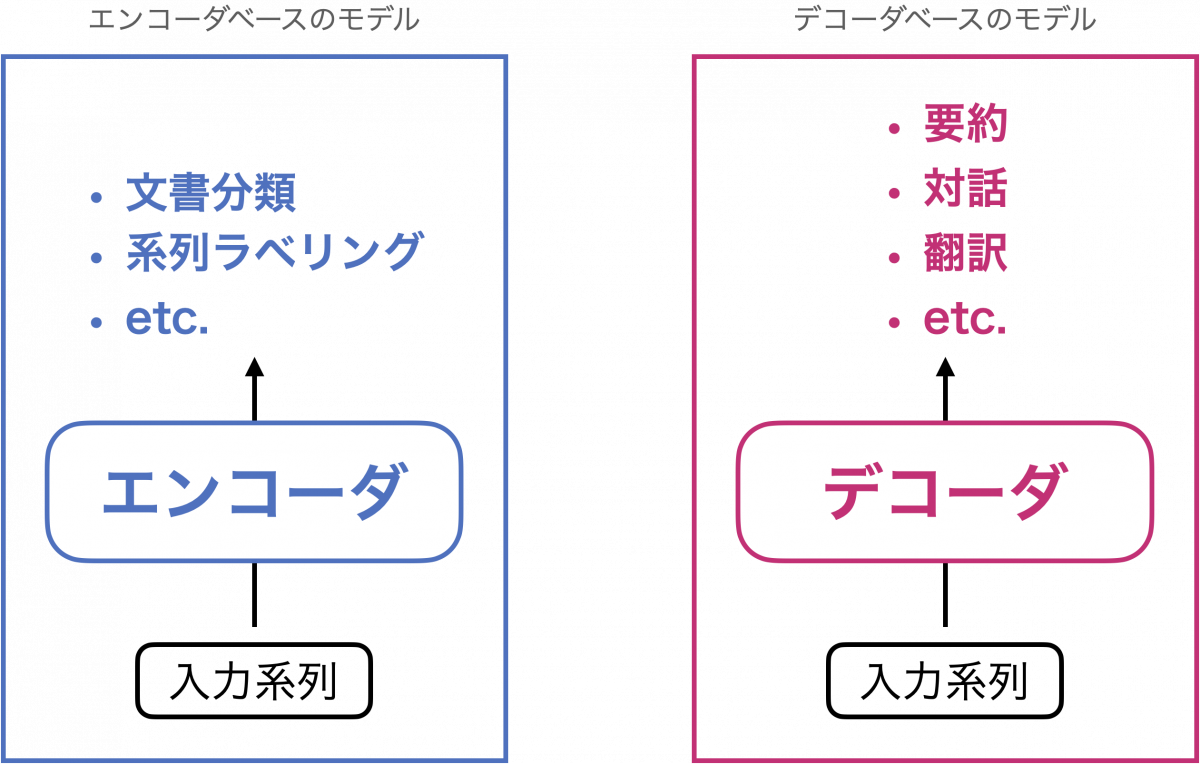
Transformer の登場以降、これをベースとしたさまざまなモデルが登場し、広く利用されています。特に自然言語処理では GPT [Radford+ 2018]、BERT [Devlin+ 2019] が先駆けです。GPT はTransformer のデコーダ部分のみを用いており、一方で BERT はエンコーダ部分のみを用いています。
GPT のようにデコーダをベースとしたモデルは、要約、対話、翻訳など、系列生成とみなせるタスクに適用しやすいモデルです。これに対して、BERT のようにエンコーダをベースとしたモデルは、入力系列の良い特徴ベクトルを文書分類に用いるという使い方が一般的です。その他に、固有表現抽出などの系列ラベリングや、文間の推論関係を予測する自然言語推論などのタスクにも BERT を適用することができます。
これらのモデルはいずれも、後続単語の予測や単語の穴埋め問題といった抽象的なタスクによってモデルをあらかじめ訓練し、その後に具体的なタスク(文書分類など)用に再学習するという手法を採っています。
あらかじめ行っておく学習を事前学習 (pre-training) と呼び、その後の再学習をファインチューニング (fine-tuning) と呼びます。
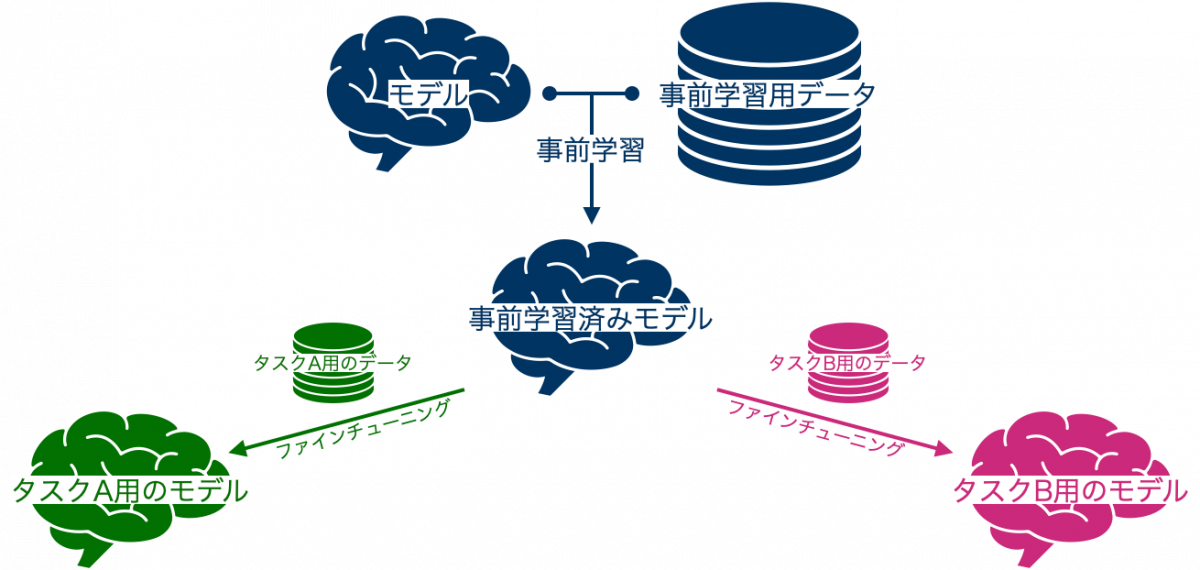
ファインチューニングなしで特定のタスク用にモデルを作る場合、モデルのパラメータをランダムな値で初期化し、そのタスク用に調整していくことになります。これに対してファインチューニングは、モデルの初期値として事前学習後のパラメータを用いることで、具体的なタスクのための学習を効率化する手法です。
ファインチューニングおよび、GPT の発展形である GPT-3 については ChatGPT の基礎技術!GPT-3 と Few-shot learning で解説していますので、こちらの記事も併せてご覧ください。
BERT のモデル機構
この後に紹介する Vision Transformer との関連も強いので、BERT の機構を下図に示します。ここでは、事前学習済みの BERT を文書分類用にファインチューニングしたと想定してください。
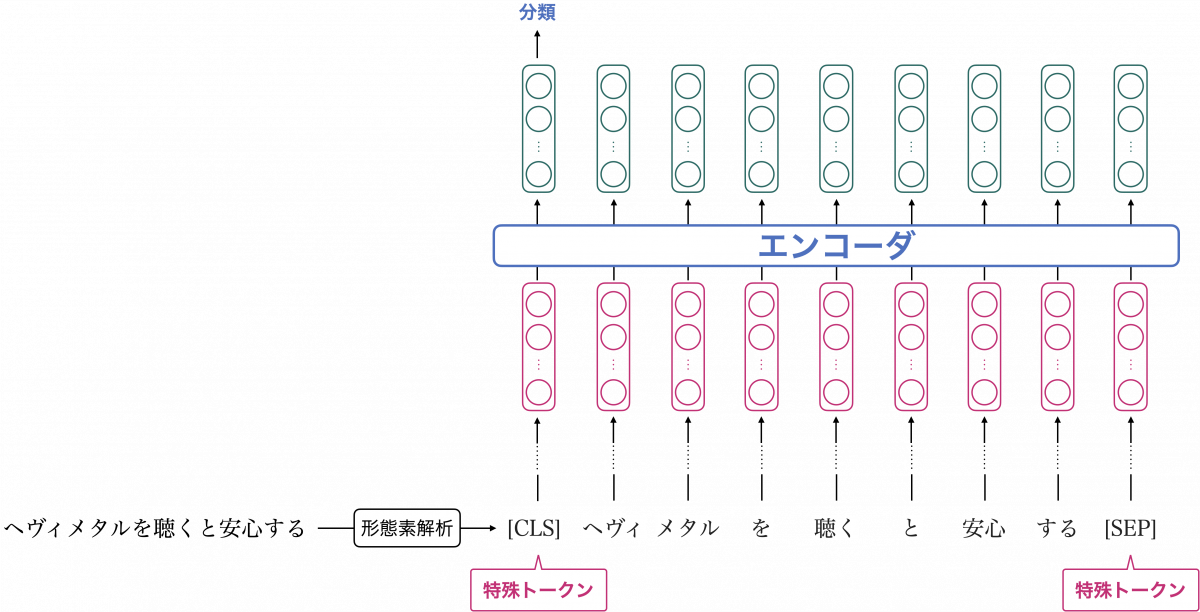
入力されたテキストは形態素解析によってトークンに分けられますが、トークンの中には [CLS] と [SEP] という特殊トークンが含まれます。[CLS] は入力テキストの先頭に置かれるトークンで、このトークンに対応する埋め込みベクトルを分類のための特徴量として用いるのが一般的です(上図を参照)。
つまり、[CLS] トークンの埋め込みベクトルは、入力テキスト全体の特徴を集約したベクトルになることが意図されています。[SEP] は複数文が入力された際の境界を表すトークンで、上図のように入力が単文の場合は末尾に置かれます。
以上に述べた BERT の機構を知っておくと、この後にご紹介する Vision Transformer の機構がとても理解しやすくなります。
ViT: 画像界の Transformer モデル
Transformer の可能性は自然言語処理以外の領域でも見出されています。ここでは、その代表例として Vision Transformer (ViT) をご紹介します。ViT は Transformer のエンコーダをベースとした画像分類モデルです。
ViT 提案論文の [Dosovitskiy+ 2020] のタイトル “An image is worth 16×16 words: Transformers for image recognition at scale” からも伺えるように、ViT は画像をいくつかのパッチに分け、それらを自然言語のトークンかのように扱います。これにより、画像データの形式と Transformer エンコーダが想定するデータの形式とを整合させています。
ViT の機構を下図に示します。
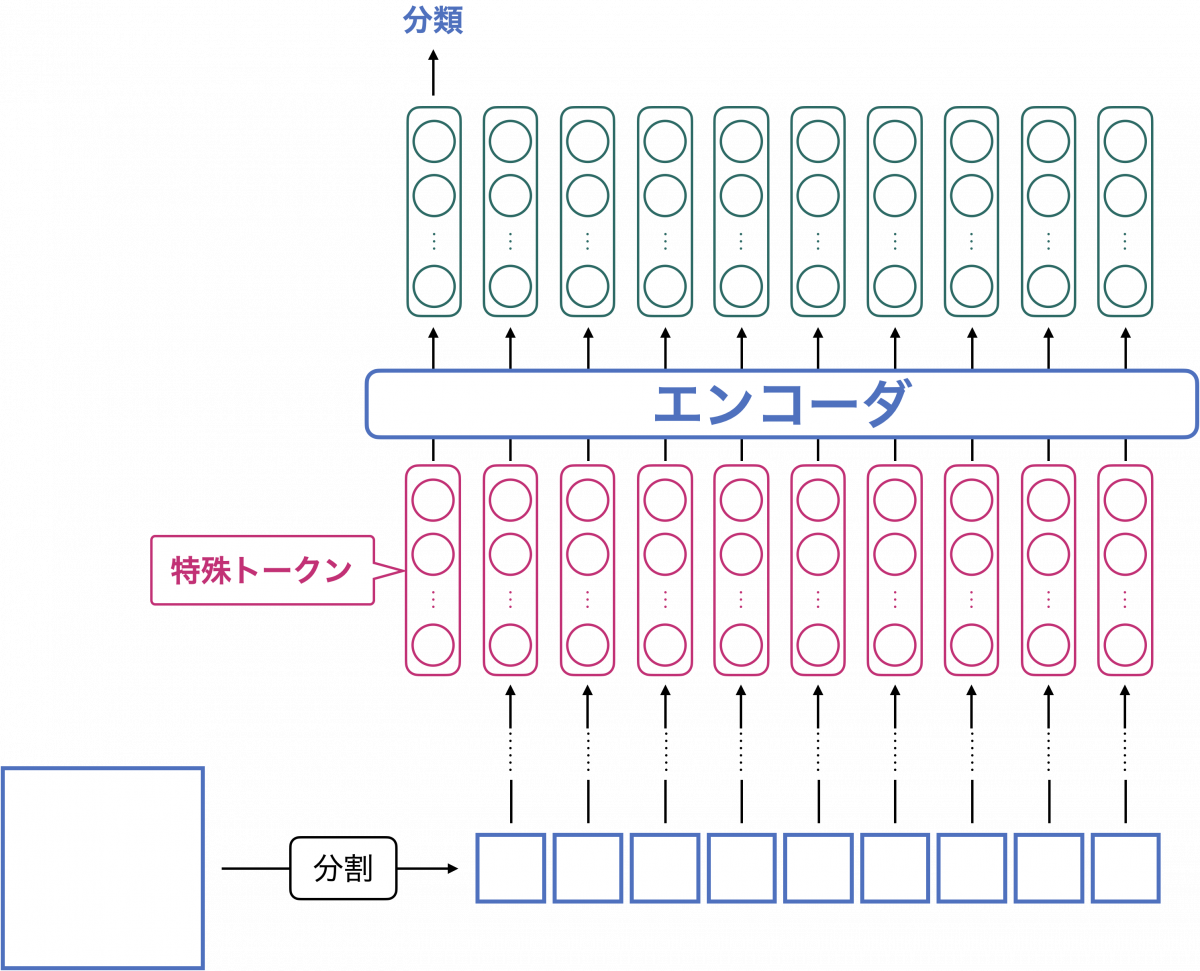
この図と先ほどの BERT の機構を見比べてみましょう。すると、BERT の場合でいう形態素解析が、ViT での画像分割に対応することがわかります。
また ViT でも、入力系列の先頭に特殊トークンが置かれ、特殊トークンに対応する埋め込みベクトルが画像分類に用いられます。
ViT 登場前の画像処理ニューラルネットワークの主流は畳み込みニューラルネットワーク (CNN) であり、現在でも特に学術的な文脈ではよく使われています。ViT の提案論文では、学習用データを十分に用意すれば、ViT は CNN に匹敵する性能を達成できると報告されています。
ViT 登場後、さまざまな改良が提案されています。Swin Transformer [Liu+ 2021] は学習の効率化および、画像分類以外のタスクへの拡張を行っています。Vivit [Arnab+ 2021] は、ViT で動画を扱うための手法を提案しています。ViT の発展型はこれら以外にも数多提案されています。興味があるものをぜひ掘り下げてみてください!
派生モデルまとめ
以上、Transformer の派生モデルをいくつかご紹介しました。どのモデルも数億スケールのパラメータ数であり、それまでの深層学習研究で得られた知見が詰め込まれています。これらのモデルを自力で実装しきるのは非常に骨の折れる作業です。
しかし心配する必要はありません。現在は、モデルそれ自体の実装にエネルギーをかけずに研究・開発するためのライブラリが整備されており、事前学習済みのモデルが非常に利用しやすくなっています。
最後に、よく使われているライブラリとして Hugging Face の提供するサービスをご紹介します。
事前学習済みモデルの活用法
Hugging Face Transformers では、事前学習済みモデルをファインチューニングするための環境が非常に利用しやすい形で提供されています。
例として、BERT 用に提供されているクラスをいくつか挙げてみます。
- 文書分類用の BertForSequenceClassification
- 系列ラベリング用の BertForTokenClassification
- 質問応答用の BertForQuestionAnswering
いま言及したクラスは学習済みモデルの雛形のようなもので、これらのクラスに学習済みのパラメータを読み込むことで事前学習済みモデルを利用することができます。学習済みパラメータは組織・個人によって Hugging Face Models に公開されており、本記事執筆時点で公開されているモデルは 238,990 件もあります。
オリジナルの BERT に対応するモデルは bert-base-uncased、bert-base-caed という名前で公開されています(大文字と小文字を区別するかどうかで二種類あります)。他にも、蒸留 (distillation) と呼ばれる手法を用いた軽量版 BERT である DistilBERT [Sanh+ 2019] や、固有表現のリンキングに優れた LUKE [Yamada+ 2020] をはじめ、多数のモデルが公開されており、目的に応じて使い分けることが可能です。
これらのツールを活用したファインチューニングの具体的な方法は、キカガクの提供する自然言語処理特化コースで取り扱っています。
まとめ
本記事では、多方面で活躍している Transformer およびその派生モデルについて解説してきました。Transformer はエンコーダ・デコーダモデルの一種であり、以下のようにご説明しました。
- エンコーダ:周辺単語を考慮したベクトル列を出力する
- デコーダ:エンコーダの出力を基に系列を生成する自己回帰型モデル
そして、重要なコンポーネントとして自己注意機構を取り上げました。自己注意機構により、周辺単語も考慮した埋め込みベクトルを得ることができます。
また、Transformer をベースとした派生モデルとして BERT、GPT、ViT をご紹介しました。Hugging Face のライブラリ等を活用して、ぜひお手元で試してみて下さい!
最後に、本記事中で言及した文献のリストを以下に示します。リストには筆頭著者名と発行年、タイトルのみを掲載しています。より詳細な書誌情報はリンク先をご確認ください。
- A. Vaswani et al., 2017, Attention is all you need. [link]
- R. Child et al., 2019, Generating Long Sequences with Sparse Transformers. [link]
- Y. Wang et al., 2019, Tree Transformer: Integrating Tree Structures into Self-Attention. [link]
- A. Katharopoulos et al., 2020, Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention. [link]
- A. Radford et al., 2018, Improving Language Understanding by Generative Pre-Training. [link]
- J. Devlin et al., 2018, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. [link]
- A. Dosovitskiy et al., 2020, An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. [link]
- Z. Liu et al., 2021, Swin transformer: Hierarchical vision transformer using shifted windows. [link]
- A. Arnab et al., 2021, Vivit: A video vision transformer. [link]
- V. Sanh et al., 2019, DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. [link]
- I. Yamada et al., 2020, LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention. [link]






まずは無料で学びたい方・最速で学びたい方へ
まずは無料で学びたい方: Python&機械学習入門コースがおすすめ

AI・機械学習を学び始めるならまずはここから!経産省の Web サイトでも紹介されているわかりやすいと評判の Python&機械学習入門コースが無料で受けられます!
さらにステップアップした脱ブラックボックスコースや、IT パスポートをはじめとした資格取得を目指すコースもなんと無料です!
最速で学びたい方:キカガクの長期コースがおすすめ

続々と転職・キャリアアップに成功中!受講生ファーストのサポートが人気のポイントです!
AI・機械学習・データサイエンスといえばキカガク!
非常に需要が高まっている最先端スキルを「今のうちに」習得しませんか?
無料説明会を週 2 開催しています。毎月受講生の定員がございますので確認はお早めに!
- 国も企業も育成に力を入れている先端 IT 人材とは
- キカガクの研修実績
- 長期コースでの学び方、できるようになること
- 料金・給付金について
- 質疑応答
DX を推進する AI ・データサイエンス人材育成コース
プログラミング未経験から、AI やデータサイエンスを学ぶことのできる 6 ヶ月間のコースです。転職実績も豊富で、自走できる AI人材を多く輩出しています。

